Der Perfekte Jodel - Teil 2
In diesem Beitrag möchte ich meine kleine Untersuchung einiger Jodel fortsetzen, die ich hier begonnen habe. In diesem Beitrag soll es um einige erste Blick auf den tatsächlichen Inhalt der Jodel gehen.
Der (vermutete) Einfluss des Themas
Ausgehend von der Hypothese, dass bestimmte Themen oder auch Erzählformen einen Einfluss auf die Menge der Upvotes haben, habe ich eine zufällige Stichprobe von 150 Jodel händisch mit einem Themen-Tag versehen. Unter “Thema” verstehe ich hier das, was van Dijk (1980:27) als Makrostruktur - “theme, topic, upshot, or gist” - bezeichnen würde.
Die vier Themenbereiche, die in der Stichprobe signifikant häufig vorkamen, sind “Witz” (32.6%), “Erlebnis” (30%), “Klage” (6.6%) sowie “Aussage” (5.3%). Um diese Kategorien etwas näher zu beleuchten, möchte ich jeweils ein zufälliges Beispiel nennen:
| Thema | Jodel |
|---|---|
| Witz | “Im Freibad T-Shirt,ausgezogen. Ein wildes Plautzi erscheint.” |
| Erlebnis | “Gerade ein Flüchtling gesehen, der mit einer Sprach-App deutsch lernt. Ungewisse Zukunft aber trotzdem versuchen sich zu integrieren. #respekt” |
| Klage | “Ich vor ner Woche: Prüfungen vorbei, endlich wieder Zeit für die Freundin, gleicher Tag: Sie macht Schluss … Ehm wow ?#twoyearsaslave #bitter” |
| Aussage | “Ich mag Leute die “seit” und “seid” unterscheiden können ??” |
Jodel vom Typ “Witz” sind oftmals Wortspiele oder direkte Nacherzählungen von Witzen. Der Typ “Erlebnis” schildert üblicherweise eine Alltagserfahrung und bewertet diese, häufig ebenfalls in humoristischer Art und Weise. Jodel vom Typ “Klage” drücken Frust über etwas aus und scheinen oft eine Art Ventil für den/die Autor/in zu sein. Ihr Gegenstück, die “Glücksbekundung”, kommt leider wesentlich seltener vor. Jodel vom Typ “Aussage” sind Feststellungen, häufig auch Anregung zu weiterer Diskussion.
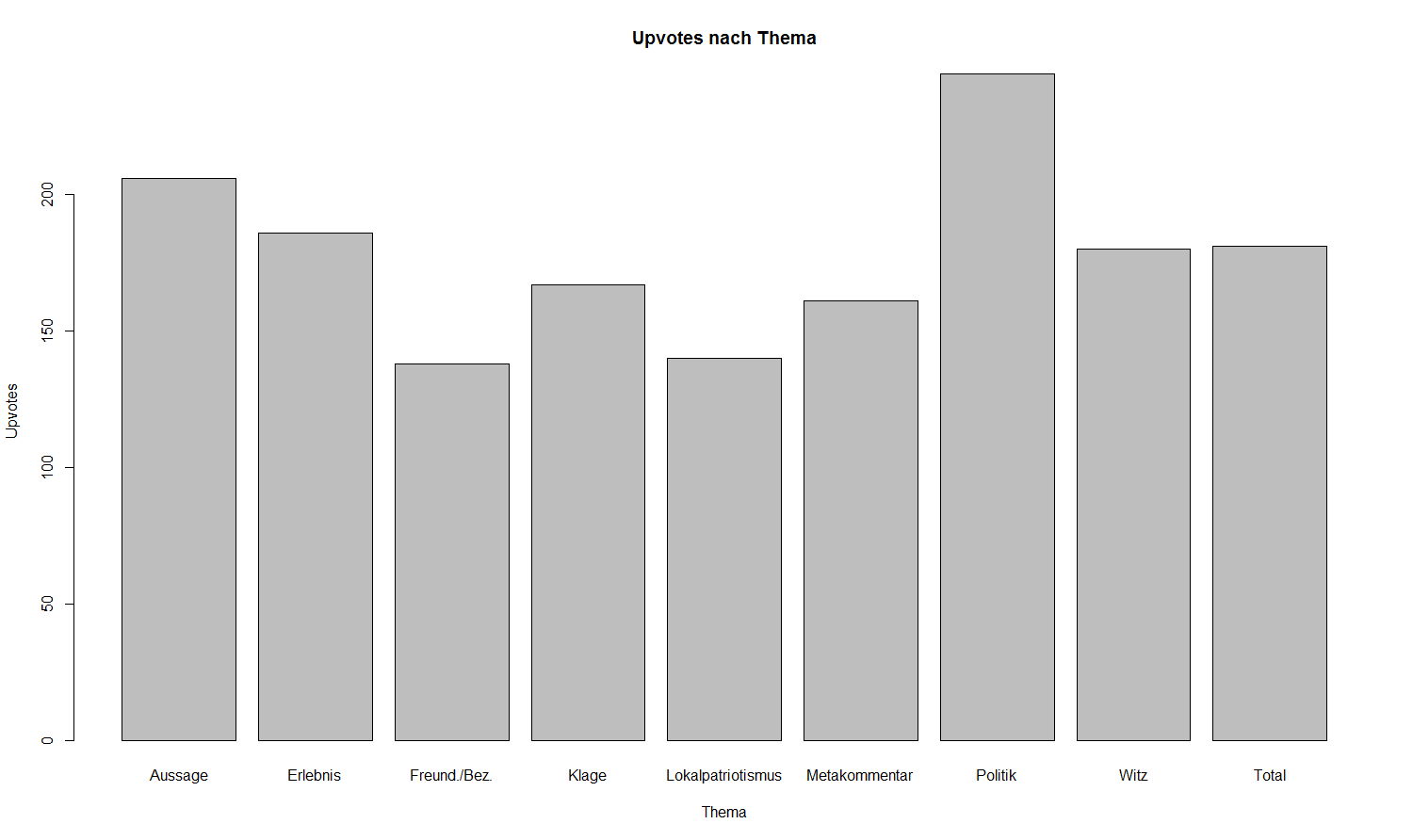
In obiger Grafik wird ersichtlich, dass die Unterschiede zwischen den Themen nur marginal sind - dies gilt insbesondere für die Themen, die signifikant häufig im Korpus/Stichprobe vorhanden waren. Eine einfach ANOVA hat gezeigt, dass der Zusammenhang von Thema und Upvotes zwar bei .106 (Eta-Squared) liegt, dieses Ergebnis aber nicht signifikant ist (p = .689). Basierend auf diesen Ergebnissen stelle ich die Themen-Upvote-Hypothese erst einmal wieder hinten an - aus einer Zeitperspektive heraus betrachtet auch nicht die schlechteste Entscheidung.
Interessanterweise hängen Thema und Länge des Jodels jedoch stark (.321) und signifikant zusammen. “Erlebnis”-Jodel sind, wie zu erwarten, mit 167 Zeichen neben Jodel zum Thema “Freundschaft/Beziehung” (173) die längsten Jodel. “Witze” (113), “Metakommentare” (117) (Jodel über Jodel), “Aussagen” (123) und “Lokalpatriotismus”-Jodel (100) sind am kürzesten. Das verwundert auch nicht, denn Storytelling erfordert häufig einen größeren linguistischen Raum. Wir erinnern uns auch daran, dass längere Jodel tendenziell mehr Upvotes erhalten. Dies könnte nun entweder tatsächlich dafür sprechen, dass längere Jodel beliebter sind, oder schlicht durch das Sample - das stark zu diesen Formen tendiert - bedingt sein.
Angemerkt werden muss aber natürlich, dass eine solche Methodologie immer Gefahr läuft, subjektive und gebiaste Ergebnisse zu erzielen, da die Annotation (trotz Grounded Theory) immer ein Stück weit eine subjektive Einschätzung bleibt.
Jodel-Plagiate
Wie schon im ersten Post angedeutet, werden Beiträge regelmäßig kopiert und weitergetragen. Da der Datensatz nur “Top-Jodel” enthält, ist anzunehmen, dass dies hier noch häufiger passiert, als bei “regulären” Jodel. Die Logik dahinter: Es könnte es eine interessante Strategie sein, erfolgreiche Jodel in einer Stadt zu “reposten” um ähnliche Karmagewinne zu erzielen wie in der ersten. Davon abgesehen sind bereits erfolgreiche Jodel schon “getestet” und haben ein sehr geringes Risiko, Negativkarma zu erhalten. Das ist zumindest so lange wahr, bis der Jodel als Repost identifiziert und von der Community abgestraft wird.
Plagiate zu finden ist eine Kunst für sich und mit Sicherheit auch eine Frage der Interpretation. In diesem Fall habe ich mich dazu entschlossen, jeden Jodel als Plagiat (Repost/Kopie) zu bezeichnen, der >60% textuelle Ähnlichkeit mit einem anderen Jodel im Korpus hat.
Diese Ähnlichkeit lässt sich mit meiner geliebten Difflib in Python schnell bestimmen:
#!/usr/bin/env python
# encoding=latin-1
from difflib import SequenceMatcher
import csv
def delta(str_a, str_b):
s = SequenceMatcher(None, str_a, str_b)
return s.ratio()
def compare_jodel(ref_jodel, ref_jodel_id):
matches = []
jodels = csv.reader(open('jodel.csv', 'rb'), delimiter=';')
for jodel in jodels:
if delta(ref_jodel, jodel[4]) > 0.6 and ref_jodel_id != jodel[1]:
matches.append(jodel)
return matchesDie Funktion compare_jodel vergleicht einen gegebenen Jodel mit dem Jodel-Korpus und gibt solche Jodel zurück, die >60% Ähnlichkeit aufweisen - potenzielle Plagiate.
Diese einfache Analyse hat gezeigt, dass (mindestens) 320 Jodel im Korpus Kopien/Plagiate sind. In anderen Worten: Rund 14% aller Top-Jodel sind Kopien aus anderen Städten beziehungsweise aus anderen Quellen.
Es ist sehr schwierig (im Grunde unmöglich) aus den Daten heraus zu bestimmten, welcher Jodel der Ursprungsjodel ist. Die Timestamps, leider nur Tagesgenau, können jedoch zumindest ein Indikator dafür sein, wo ein Jodel zuerst “aufgetaucht” ist - mögliche Zwischenschritte werden natürlich nicht erfasst.
Eine Stichprobe hat ergeben, dass es vermutlich keine echte First Mover Advantage gibt. Es ist aber anzunehmen, dass es in Ballungsgebieten negative Effekte haben könnte, Jodel in weniger weit entfernen Städten zu reposten, da die Jodel-Community eine tendenzielle Abneigung gegenüber solchen Kopien hat.
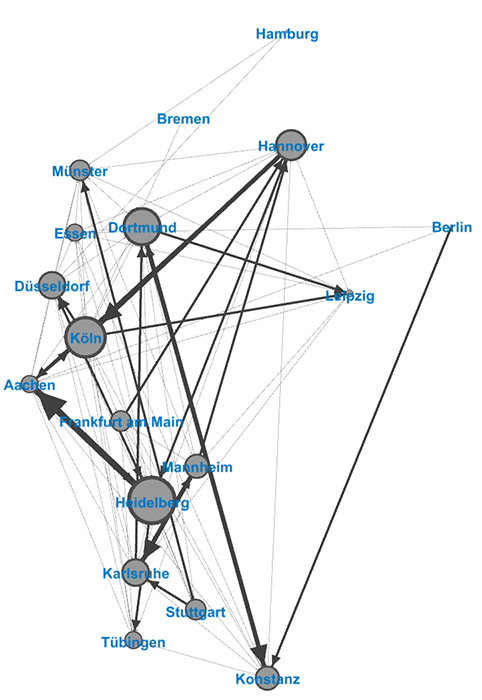
Versucht man, basierend auf den Timestamps, den “Weg” der Plagiate zu verfolgen, ergibt sich obiges Bild. Die Datenbasis für diese Darstellung ist allerdings extrem schwierig: Nur wenige Plagiate lassen sich (relativ) Eindeutig zeitlich festlegen (oftmals erscheinen Reposts in mehreren Städten am selben Tag) und mögliche Zwischenstationen, Abkürzungen, etc. können, aufgrund der Korpusgröße, schlicht nicht bestimmt werden.
Nichtsdestrotz lässt sich zeigen, dass es sowohl lokalen Austausch (z.B. in der Rhein-Neckar Region und im Ruhrgebiet) als auch einen Nord-Süd Austausch gibt. Die Dicke der Linien gibt hierbei die Häufigkeit der Plagiate an, die Größe der Kreise zeigt, welche Städte (vermutlich) besonders “innovativ” sind und mehr oder weniger viele Jodel “als erstes” gepostet haben. Neben einigen sehr etablierten Verbindungen (z.B. Heidelberg-Aachen, Dortmund-Konstanz, Mannheim-Karlsruhe) lassen sich einige Zentren im Netzwerk ausmachen, die offenbar sehr gut an das “Jodel-Netz” angebunden sind.
Innerhalb der größeren Zentren, zum Beispiel im Dreieck aus Mannheim, Heidelberg und Karlsruhe, werden Jodel häufig noch am selben Tag in mehreren Städten gepostet. Reposts werden hier aber oftmals schnell erkannt.
Plagiate im Detail
Betrachtet man die auftretenden Plagiate genauer, stellt man schnell fest, dass Jodel oft nicht eins zu eins kopiert werden. In vielen Fällen finden Anpassungen, zum Teil tatsächlich Kreativleistungen statt.
Drei besonders produktive Typen von Plagiaten (Remixes?) sind Lokalisierungen (Beispiele: 1 & 2 ), Detailveränderungen (Beispiele: 3 & 4) und Erweiterungen (Beispiele: 5 & 6):
- Beispiel 1:
- “Hab gestern im Bett extra ein DB T-shirt getragen. …bin trozdem zu früh gekommen.” (Dortmund)
- “Gestern beim Sex extra eine KVB Jacke angezogen… …und trotzdem zu früh gekommen… ?” (Köln)
Hier wird der Deutsche-Bahn (DB) Kontext auf die Kölner Verkehrs-Betriebe (KVB) zugespitzt und so eine Lokalisierung des Jodels vorgenommen.
- Beispiel 2:
- “Keine Ampel, jemals.” (Münster)
- “-keine Stuttgarter Ampel, jemals” (Stuttgart)
In diesem einfachsten Fall der Lokalisierung wird eine Sache oder Person schlicht einem Ort zugeschrieben, in diesem Fall Stuttgart.
- Beispiel 3:
- “Einen Dreier zu schieben ist beschissener als man denkt … Erkan 21, hat vergessen zu tanken” (Frankfurt am Main)
- “Einen dreier zu schieben ist beschissener als man denkt. Erkan, hat vergessen zu tanken” (Leipzig)
- “Einen dreier zu schieben ist schwerer als man denkt! Ali 23, hat vergessen zu tanken” (Tübingen)
In diesem Beispiel spielt es keine Rolle, ob es sich um Ali oder Erkan handelt, es muss schlicht das Klischee/Stereotyp eines “Türkens” bedient werden um den Witz zu realisieren.
- Beispiel 4:
- “Kriegserklärung einer Frau : ‘Aha’” (Düsseldorf)
- “Kriegserklärung einer Frau: ‘Aha?!’” (Heidelberg)
Hier wollte der/die Autor/in des zweiten Jodels durch ein Interrobang verstärken und Nackdruck auf das “Aha” legen.
- Beispiel 5:
- “Zimmerventilatoren sind eigentlich Hubschrauber, die irgendwann ihre Träume aufgeben und sich einen kleinen Bürojob gesucht haben.” (Heidelberg)
- “Zimmerventilatoren sind eigentlich Hubschrauber, die irgendwann ihre Träume aufgegeben und sich einen kleinen Bürojob gesucht haben.” (Frankfurt am Main)
- “Zimmerventilatoren sind eigentlich Hubschrauber, die irgendwann ihre Träume aufgegeben und sich einen kleinen Bürojob gesucht haben. -mir, gerade eingefallen, als ich meinen einsamen Tischventilator abgeschaut habe.”
Im dritten Fall hat der/die Autor/in den Jodel um Kontext erweitert und sich eines Anthropomorphismus bedient.
- Beispiel 6:
- “40 Pokémon in 2 Stunden. 0 Dates in 23 Jahren.”
- “20 Pokemon in 2 Stunden 0 Dates in 20 Jahren #lebenkannich #prioritäten”
Hier hat der/die Autor/in den Jodel angepasst und um zwei Hashtags erweitert, die eine explizite Bewertung vornehmen, die eigentlich schon implizit vorliegt.
Alles in allem konnte ich keinen eindeutigen Einfluss dieser Strategien auf die Upvotes feststellen. Intuitiv scheint die Kombination aus erprobtem (d.h. kopiertem) Inhalt und Anpassungen - insbesondere an die lokale Jodel-Community - eine gute Strategie für schnelle Karmagewinne zu sein.
Einfache Sentiment-Analysis
Die sogenannte Sentiment-Analysis versucht eine automatisierte Aussage darüber zu treffen, ob eine geäußerte Haltung eher positiv oder eher negativ ist. Während es wundervoll komplexe Verfahren gibt, dieses Problem zu lösen (üblicherweise mithilfe von Bayes-Klassifikatoren und anderen machine-learning Verfahren), habe ich mit entschlossen, den einfachsten Weg zu gehen.
Mit SentiWS hat die Universität Leipzig eine Sammlung von positiv und negativ konnotierten Wörtern (Deutsch) veröffentlicht, die nicht nur nach Wortart, sondern auch nach Sentiment getaggt sind. Eine ganz einfache Sentiment-Analysis lässt sich nun durchführen indem man schlicht die negativen, beziehungsweise positiven Begriffe in einem Satz (oder Jodel) gegeneinander aufrechnet.
Das folgende Python Script erzeugt basierend auf dieser einfachen Methode z.B. folgende Ergebnisse:
| Jodel | Sentiment (Total) | Sentiment (Mittelwert) |
|---|---|---|
| “Bestes Passwort: falsch Wenn man sein Passwort falsch eingibt, steht dort: “ihr Passwort ist falsch” #oldbutgold” | -1.5236 | -0.089623529 |
| “Eins muss ich meiner Faulheit ja lassen. Kondition hat sie.” | -0.611 | -0.0611 |
| “Ich kann gut Mitmenschen umgehen. Holger, 32, Informatiker” | 0.3716 | 0.04645 |
| “Unterm Strich ist alles gut _____ ????????” | 0.3716 | 0.053085714 |
Die beiden oberen Beispiele bekommen einen negativen Score - sie werden vom Algorithmus als eher negativ eingestuft. Für die beiden unteren Beispiele gilt das Gegenteil.
Während diese Herangehensweise grundsätzlich relativ gute und nachvollziehbare Ergebnisse erzielen kann, wird schon an diesen wenigen Beispielen schnell deutlich, dass die sprachliche Komplexität nicht wirklich abgebildet werden kann. Im zweiten Beispiel ist der Begriff Faulheit zwar korrekterweise als negativ markiert, der Computer übersieht aber natürlich, dass es sich um ein Witz handelt.
#!/usr/bin/env python
# encoding=latin-1
import sys
import nltk
import csv
reload(sys)
sys.setdefaultencoding('latin-1')
sentiws_words = list(csv.reader(open('SentiWS_v1.8c.txt', 'rb'), delimiter='|')) # Negative and Positive combined
def get_word_score(word):
# Stemming
# stemmer = nltk.SnowballStemmer("german")
# word = stemmer.stem(word)
try:
pos = [item[0] for item in sentiws_words].index(word)
score = sentiws_words[pos][1].split()[1]
except:
score = 0
finally:
return float(score)
def get_string_score(string):
words = string.split()
aggregate_score = 0
for word in words:
aggregate_score = aggregate_score + get_word_score(word)
#return aggregate_score/len(words) # Average
return aggregate_score
# Analyze Jodels
results_file = open('results.txt', 'w')
jodels = list(csv.reader(open('jodel_sa.csv', 'rb'), delimiter=';'))
print jodels[0][4]
for jodel in jodels:
if len(jodel[4]) > 0:
result = str(get_string_score(jodel[4]))
else:
result = '0'
results_file.write(result + '\n')
results_file.close() Die Analyse hat gezeigt, dass es keinen signifikanten Zusammenhang zwischen positiven Jodel (positiv im Sinne der obigen Methode) und der Zahl der Upvotes gibt. Es lässt sich höchstens eine sehr leichte Tendenz erkennen, die dafür spricht, dass positive Jodel tendenziell mehr Upvotes erhalten könnten. Diese Erkentniss würde sich mit meiner intuitiven Erwartungshaltung - Jodel erfüllt in erster Linie einen Entertainmentzweck - decken.
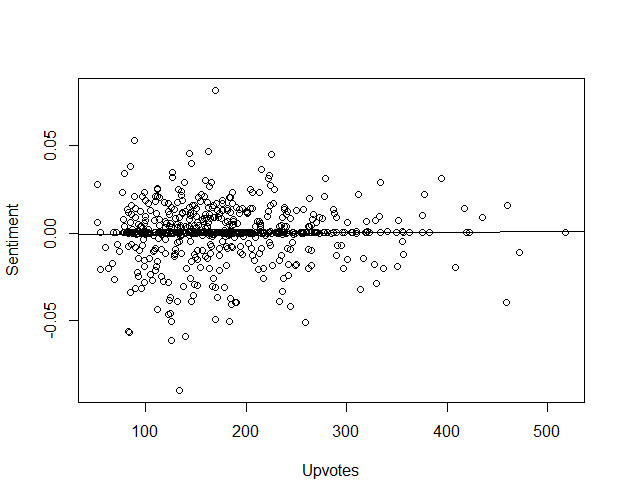
Eine qualitative Auswertung einiger Jodel hinsichtlich des Positiv/Negativ Merkmals hat ebenfalls gezeigt, dass kein eindeutiger Zusammenhang ersichtlich ist. Eine tiefere und fundiertere Analyse scheint daher, in anbetracht des Aufwandes, an dieser Stelle erst einmal nicht besonder gewinnbringend.
Was wir neues wissen
Leider hat diese kurze Betrachtung einiger Inhaltsaspekte weniger eindeutige Ergebnisse geliefert, als die strukturelle Analyse. Das ist aber, gegeben des höheren Komplexitätsniveaus, auch kein unerwartetes Ergebnis. Trotzdem lassen sich folgende Erkentnisse festhalten:
- Das Thema eines Jodels scheint erst einmal keinen direkten Einfluss auf die Upvotes zu haben. Allerdings sind die meisten der Top-Jodel “Witze” oder “Erlebnisberichte”, was für diese beiden Kategorien sprechen würde.
- Ein signifikanter Teil der Jodel sind (leicht veränderte) Kopien von bereits bestehenden Jodel. Diese werden sowohl lokal als auch deutschlandweit weitergetragen. Die Intuition sagt, dass es aus einer Upvote-Maximierungsperspektive heraus sinnvoll erscheint, Jodel über größte Distanzen hinweg - idealerweise in weniger vernetze Städte - zu kopieren.
- Das rein lexikalisch vermittelte Gefühl eines Jodels (positiv/negativ) hat keinen Einfluss auf die Upvotes. Es scheint eine Tendez dahin zu geben, dass positive Jodel tendenziell bessere Ergebnisse erzielen.
Quellen
R. Remus, U. Quasthoff & G. Heyer: SentiWS - a Publicly Available German-language Resource for Sentiment Analysis. In: Proceedings of the 7th International Language Ressources and Evaluation (LREC’10), pp. 1168–1171, 2010
van Dijk, Teun A. 1980. Macrostructures. Hillsdale, N.J. L. Erlbaum Associates.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn