Extracting Keywords from Newspapers via newspaper
Newspapers and especially online news portals (e.g. The New York Times Online) are invaluable (linguistic) sources for many research projects in various field (e.g. discourse analysis, media studies, etc.).
However, systematically acquiring such data, speaking from experience, is often harder than expected. Even if one is lucky enough to have (institutional) access to databases and tools such as LexisNexis it can be extremely tedious to build a (simple) newspaper/article corpus in a sane format (i.e. not having unstructured PDF files).
I recently stumbled across newspaper / newspaper3k, an amazing little Python library that makes this whole thing a whole lot easier.
newspaper by Lucas Ou-Yang
newspaper (recently ported to Python 3 ❤) allows us to find, extract, download, and parse articles from a potentially unlimited number of sources. Also, this works relatively seamlessly across 10+ languages. If that weren’t enough, newspaper is capable of caching articles, multi-threaded downloads, and basic NLP.
Downloading and parsing an individual article is as simple as:
from newspaper import Article
article = Article('https://www.nytimes.com/2017/12/01/opinion/trump-national-monuments-bears-ears.html')
article.download()
article.parse()
article.nlp()
>>> article.authors
['Bruce Babbitt']
>>> article.text
"Photo\n\nAmerica's wild places survive..."
>>> article.keywords
['national', 'president', 'american', 'monuments', 'york', ...]This, in itself, is already great! However, the real power of newspaper is in constructing (or building) (online) corpora of articles automatically. I decided to demonstrate this feature in a very simple and more or less pointless case study on the differences between three news categories of the Telegraph.
I will also quickly introduce an additional feature that I recently have added to newspaper (well, at least my fork of it).
Extracting Keywords from the Telegraph
Keywords, put simply the allegedly ‘most important words of a text/corpus’, often provide a brilliant entry into understanding what a certain text or collection of texts is about. In the terms of corpus linguistics, the notion of keyword (positive keywords, negative keywords, and lockwords) refers to words that are over/underrepresented regarding a second corpus.
How to Find Keywords?
Generally speaking there are (at least) three ways of extracting keywords:
- Purely based on frequency, i.e. how often a certain word/token exists in the corpus. This does not take into account a second corpus. (This is what happens under the hood [
keyword()innlp.py] in newspaper by default.) - By comparing the frequency table of one corpus (the target) to another corpus (the reference) and highlighting over-/underrepresented, statistically significant, differences. (This is the additional functionality that I have added to newspaper.)
- Using machine learning and/or deep learning models to extract keywords.
Especially this second method is interesting because it is one of the standard tools used by corpus linguistics. While there are some considerable issues regarding log-likelihood and others such as Chi-Squared (see e.g. Gablasova et al. 2017), this methods in many cases still produces some very helpful results.

Corpora
In order to exemplify newspaper, I will collect three small corpora, each containing articles from a specific category of news (i.e. education, politics, sports). I will then extract and summarize the keywords of these categories. Based on these keywords we should be able to clearly distinguish between the three categories and make an assumption about the underlying topic or category.
Again, from a research standpoint this is rather pointless. It’s just a straightforward example 😃.
Code and Analysis
I will start by just showing you the code (licensed under the CRAPL).
import newspaper
import pickle
import os.path
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from collections import Counter
keywords = []
keywords_rc = []
# Define the source, title, and category
source_url = 'http://www.telegraph.co.uk/'
source_name = 'The Telegraph'
category = 'education'
if not os.path.isfile(source_name + 'keywords.p'):
# Building the corpus; momize_articles=False disables the caching
paper = newspaper.build(source_url, memoize_articles=False)
for article in paper.articles:
if category in article.url:
article_counter =+ 1
article.download()
article.parse()
article.nlp(reference_corpus='coca_sampler.txt')
keywords = keywords + article.keywords
keywords_rc = keywords_rc + article.keywords_reference_corpus
pickle.dump(keywords, open(source_name + category + 'keywords.p', 'wb'))
pickle.dump(keywords_rc, open(source_name + category + 'keywords_rc.p', 'wb'))
else:
keywords = pickle.load(open(source_name + category + 'keywords.p', 'rb'))
keywords_rc = pickle.load(open(source_name + category + 'keywords_rc.p', 'rb'))
# Constructing two dataframes, one for each of the keyword extraction methods
keywords = Counter(keywords)
keywords_rc = Counter(keywords_rc)
df = pd.DataFrame.from_dict(keywords, orient='index').reset_index()
df = df.rename(columns={'index': 'Keyword', 0: 'Frequency (Articles)'})
df = df.sort_values(by=['Frequency (Articles)'], ascending=False)
df_rc = pd.DataFrame.from_dict(keywords_rc, orient='index').reset_index()
df_rc = df_rc.rename(columns={'index': 'Keyword', 0: 'Frequency (Articles)'})
df_rc = df_rc.sort_values(by=['Frequency (Articles)'], ascending=False)
# Data Visualization
how_many = 20
sns.set_style("whitegrid")
fig, axs = plt.subplots(ncols=2)
sns.barplot(x='Keyword', y='Frequency (Articles)', data=df[:how_many], ax=axs[0]).set_title('Keywords')
sns.barplot(x='Keyword', y='Frequency (Articles)', data=df_rc[:how_many], ax=axs[1]).set_title('Keywords COCA')
plt.setp(axs[0].xaxis.get_majorticklabels(), rotation=45)
plt.setp(axs[1].xaxis.get_majorticklabels(), rotation=45)
plt.suptitle('{} ({})'.format(source_name, category))
fig.set_size_inches(20, 10)
plt.savefig(source_name + '.png', dpi=300)After configuring the source (via an URL), the title, and a desired category (i.e. a specific part of the URL), a news source object is created that stores references to all articles.
According to the documentation, a news source object contains “a set of recent articles”. More precisely, newspaper is crawling the page it has been pointed to. Ultimately, this means that pointing newspaper to an URL (let say http://www.telegraph.co.uk) will not necessarily return all articles. We would’ve to implement something that crawls every page and the archive on our own. For this example, I have not bothered to do so. Hence, I will be using the articles (approximately 100 per category) that newspaper produced by default.
Afterwards, the individual articles are checked for being part of the specific category in question, downloaded, and parsed.
For keyword extraction, as said before, I’m relying on my own fork of newspaper that can be found on my GitHub.
For each article, the keywords are extracted with the standard method and via comparing the article to the Corpus of Contemporary American English as a reference corpus. Of course, since this is a British newspaper, the choice of reference corpus here is not ideal. At the same time, the COCA sampler is very easy to manage and generally produces good results for contemporary English. If you wanted to do this right, the new BNC 2014 would’ve been a much better choice though…
The keyword results for all articles are then aggregated and visualized as a barchart using Seaborn.
For both methods of extracting keywords, stopwords (i.e. highly frequent and very common words) have been removed. Internally, newspaper currently relies on this stopword list for English.
Results and Conclusions
The results for the three categories can be seen here. For each category the 20 most frequent keywords are shown.
Education
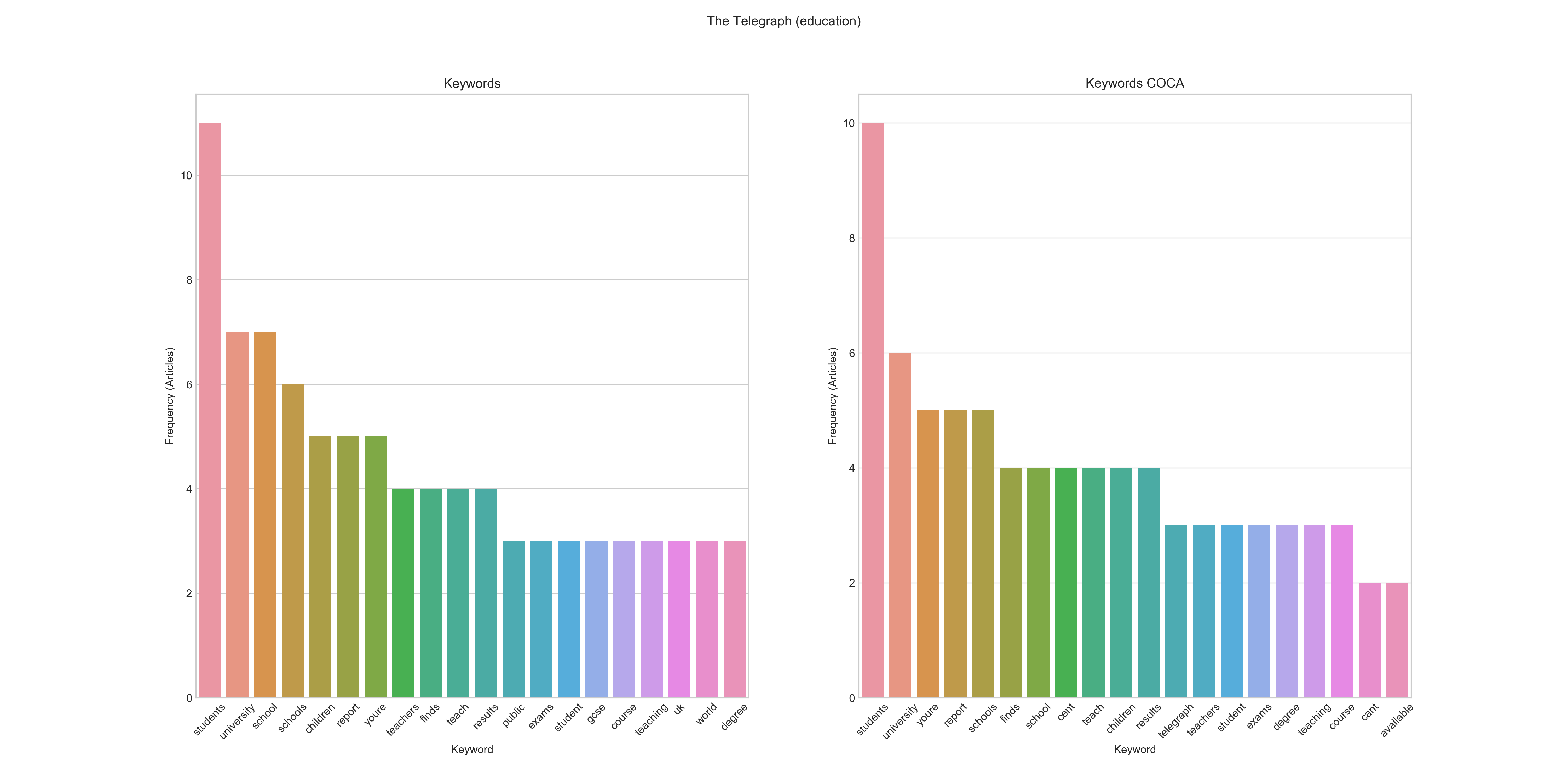 Aggregated Keyword Frequency Graphs for Education / The Telegraph 2017
Aggregated Keyword Frequency Graphs for Education / The Telegraph 2017
Frequency: students, university, school, schools, children, report, youre, teachers, finds, teach, results, public, exams, student, gcse, teaching, uk, world, degree Frequency COCA: students, university, youre, report, schools, finds, cent, teach, children, results, telegraph, teachers, student, exams, degree, teaching, course, cant, available
In the education subcorpus students, university, and school(s) are frequent keywords for both retrieval methods. The case of telegraph being a keyword in the COCA variant is a good example of how the comparison works. Since telegraph is certainly overrepresented in the target corpus, as compared to a representative corpus of American English, it will be recognized as a keyword.
Politics
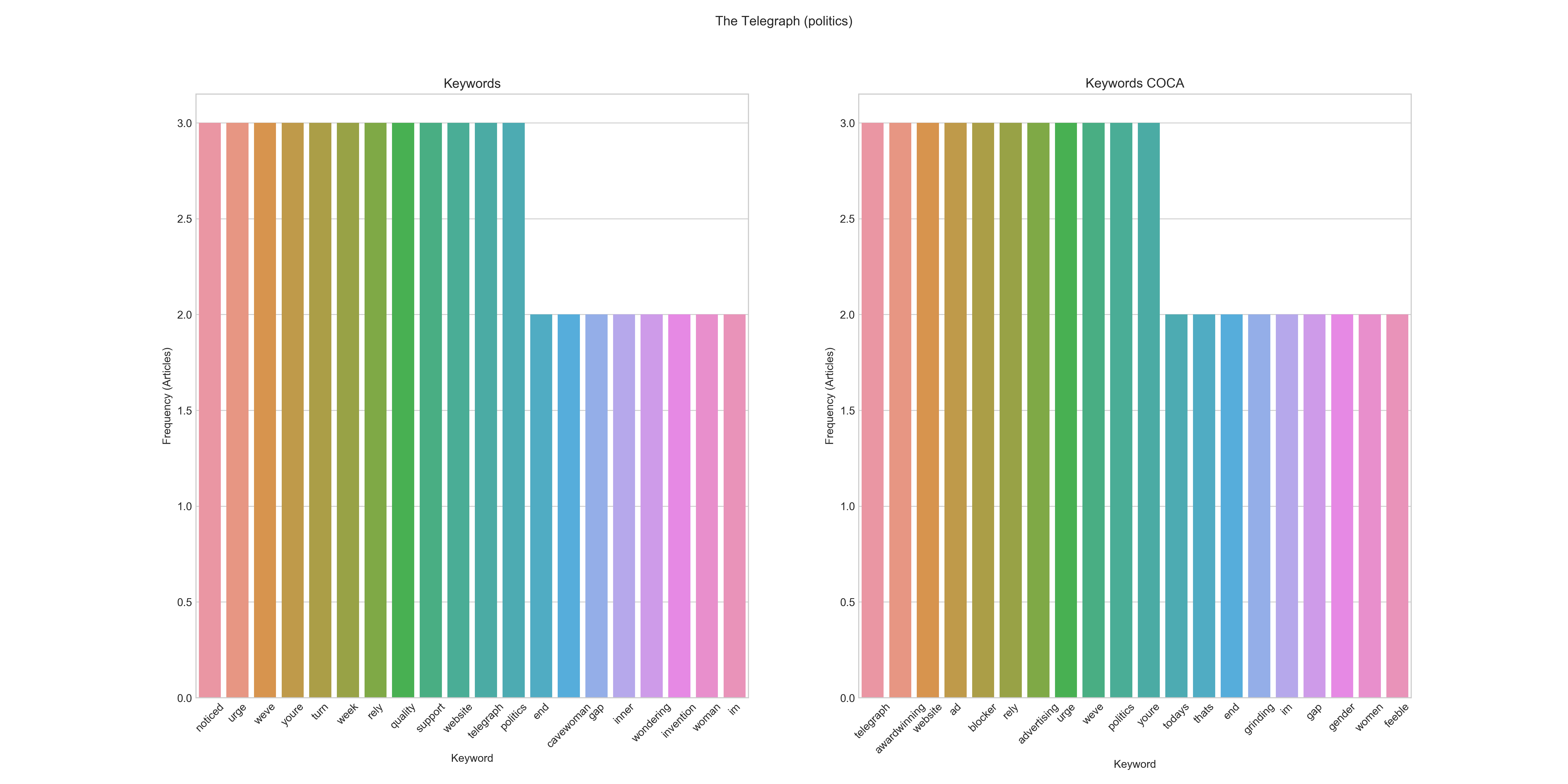 Aggregated Keyword Frequency Graphs for Politics / The Telegraph 2017
Aggregated Keyword Frequency Graphs for Politics / The Telegraph 2017
Frequency: noticed, urge, weve, youre, turn, week, rely, quality, support, website, telegraph, politics, end, cavewoman, gap, inner, wondering, invention, woman, im Frequency COCA: telegraph, awardwinning, website, ad, blocker, rely, advertising, urge, weve, politics, youre, todays, thats, end, grinding, im, gap, gender, woman, feeble
In the case of the category politics the results are harder to interpret. There aren’t any keywords that turn up really frequently (if we look at them in an aggregated fashion), but many individual keywords with just one or two hits in all of the articles. While we certainly can guess the category from the keywords, there seems to be a more diverse set of topics/keywords. The statistical comparison at least was able to uncover the gender/woman/(gender) gap topic. However, based on these results, we would have to look at individual articles more closely.
Sports
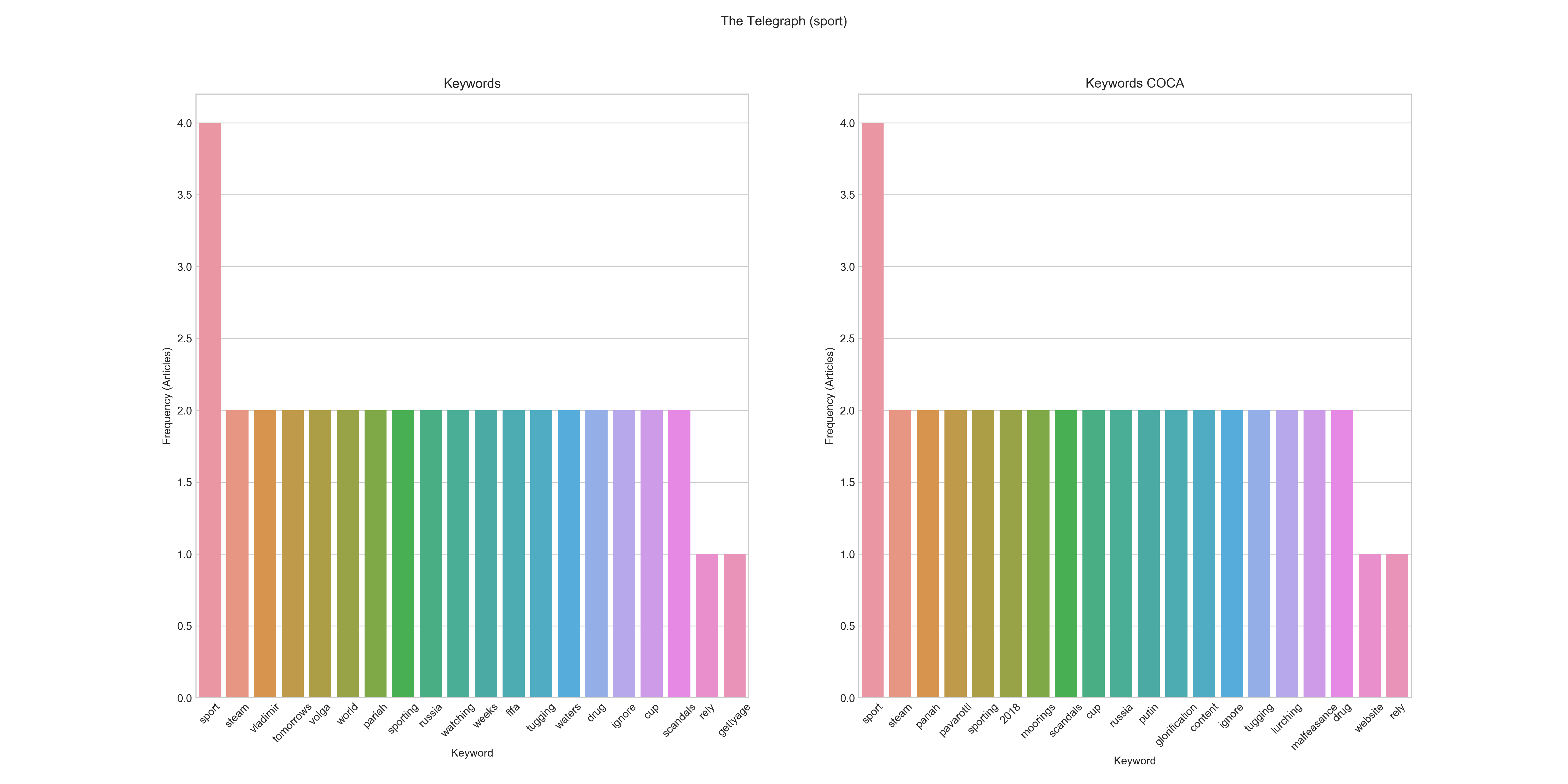 Aggregated Keyword Frequency Graphs for Sports / The Telegraph 2017
Aggregated Keyword Frequency Graphs for Sports / The Telegraph 2017
Frequency: sport, steam, vladimir, tomorrows, volga, world, pariah, sporting, russia, watching, weeks, fifa, tugging, waters, drug, ignore, cup, scandals, rely, gettyage Frequency COCA: sport, steam, pariah, pavarotti, sporting, 2018, mooring, scandals, cup, russia, putin, glorification, content, ignore, tugging, lurching, maldeasance, drug, website, rely
The sport subcorpus tells a very similar story. While it is clear that sport is in fact a keyword, the range of keywords, based on the individual articles, seems to be rather broad. Interestingly, the statistical keyword extraction has revealed some interesting additional keywords (albeit with low frequencies) such as putin and glorification.
It’s also important to notice that, since I’ve presented absolute, non-normalized, frequencies here we cannot compare the number of occurrences between the three subcorpora.
There are basically three major results we can draw from this:
- The three categories, in terms of keywords, are clearly distinguishable. In other words, we can clearly judge the category (or even genre) based on the keywords.
- The two types of keyword extraction lead to different results. Neither of the two methods is clearly superior to the other, but they serve different purposes. As this simple example has shown, the statistical/comparison method can reveal some relevant keywords even though they are low in frequency.
- Looking at aggregated keywords reduces complexity, but also obfuscated interesting details within these subcorpora.
In conclusion, newspaper is a great library that does a great job at interfacing with newspaper sites. At the same time, and this is not newspaper’s fault at all, we should not forget that research design and corpus compilation need to be driven by theory and thought and not by the availability of technology.
Works Cited
Gablasova, D., Brezina, V., & McEnery, T. (2017). Exploring Learner Language Through Corpora: Comparing and Interpreting Corpus Frequency Information. Language Learning, 67 (S1), 130–154.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn