Utilizing TextDirectory for Corpus Compilation and Management
In corpus linguistics and NLP we are often faced with data in plain text format. More often than not, although various databases are becoming more common, corpora exist as a collection of text files.
While most NLP libraries are perfectly well equipped to deal with this, I often find myself chaining various bash commands/tools to manage these types of corpora.
Often, I don’t want or need the ‘overhead’ of fully fledged text-processing suites, but just a simple tool to deal with large amounts of text files. One of the most common, most trivial, and most boring tasks is aggregating various text files based on some criteria, for example, content or length. Also, sometimes I want to quickly draw a random sample of files.
TextDirectory
While this task has been solved over and over, I recently decided to put my own tooling (basically a couple of Python scripts) into a small library that would work just the way I need it to work. Ultimately, I just needed a tool that would take a folder filled with text files and aggregate these files into one.
![]()
The result of this endeavor, a library and CLI-tool called TextDirectory, is based on a two stage process. While in the first stage a number of filters can be used to select appropriate documents (files), a second step allows me to perform some rather basic transformations on the text.
In both stages, the filters and transformations can be chained and repeated in an arbitrary order. This iterative approach to data selection (and manipulation) leads to a quite flexible and powerful tool.
Example - Contemporary Corpus of American English
In order to demonstrate this capability, I will create a sub-corpus from the current COCA-Sampler based on some (arbitrary) criteria.
The Corpus of Contemporary American English, in its simplest form, comes as a collection of text files with file names indicating their content, e.g. 2017_news.txt for news related texts from 2017.
For this example I will be using TextDirectory as a Python library. However, the very same functionality is available via the CLI on the command line.
The simplest thing we can do is aggregating all files and reading them into memory:
import textdirectory
td = textdirectory.TextDirectory(directory='coca2017_text')
td.load_files()
aggregated = td.aggregate_to_memory()
print(aggregated)Well, this (more or less) could have been achieved by simply calling cat *.txt >> .txt.
So, let’s introduce some constraints. Let’s say we want two files (randomly sampled) from 2017 that fall within two standard deviations in length and each have at least 100 tokens. We also want the end result to be in lower-cased and we also need to remove any line-breaks.
Within the framework of TextDirectory we need something like this:
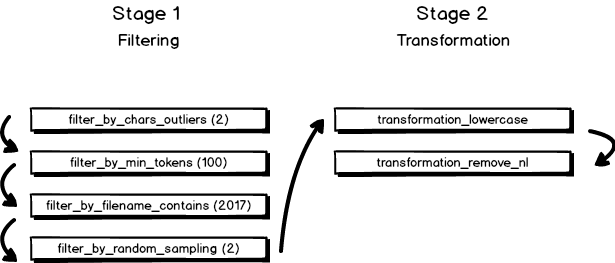
In stage one we are filtering for outliers, the minimum number of tokens, and the file name (as a proxy for the year). Afterwards, we are drawing a random sample from that data selection. Each filter step builds on the previous one. Hence, when we are looking for files that have no less than 100 tokens, we are doing this on a data set that has already been filtered for outliers.
In stage two we are transforming all documents (on export/aggregation) to lowercase and remove the linebreaks. we are ‘staging’ these operations because they will only be executed during the actual aggregation. TextDirectory is designed to hold as little data in memory as possible in order to be able to handle large amounts of files. Therefore, we are not doing the transformation ‘live’.
The same example in (very explicit) Python:
import textdirectory
td = textdirectory.TextDirectory(directory='coca2017_text')
td.load_files()
td.filter_by_chars_outliers(2)
td.filter_by_min_tokens(100)
td.filter_by_filename_contains('2017')
td.filter_by_random_sampling(2)
td.stage_transformation(['transformation_lowercase'])
td.stage_transformation(['transformation_remove_nl'])
td.print_aggregation()
aggregated = td.aggregate_to_memory()
td.aggregate_to_file('agg.txt')As this example hopefully has shown, TextDirectory can solve some rather tricky tasks in an intuitive and flexible way. That being said, I am fully aware of the fact that there are much more elaborate (and tested) solutions for similar problems. Nevertheless, this works quite well for me and feedback is absolutely welcome!

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn