Demystifying Vector Stores – A (LangChain) Vector Store from Scratch

Especially over the last two years, alongside the development of Large Language Models (LLMs), vector stores and databases have become a hot topic and have seen widespread adoption.
Put simply, they are used to store vectors (often embeddings) so that they can be (efficiently) used in machine learning (ML) applications and pipelines.
In this article, I will demistify, at least to a point, these databases. First, I will provide some helpful background information for you to gain an intuition about the technology and its purpose. Then, I will be implementing a simple, in-memory vector store in Python that is compatible with LangChain.
If you are already conceptually familiar with Embeddings, Vector Stores, Cosine Similarity, and Retrieval-Augmented Generation, you can safely just skip down to the implementation.
Background
In the following, I will introduce vector stores and databases, the concept of embeddings, cosine similarity as a means of comparing vector similarity, and Retrieval-Augmented Generation as a common use case for vector stores.
Vector Stores and Vector Databases
Both vector stores and databases are used to store, manage, and retrieve vectors efficiently. As vectors, especially embeddings, are increasingly used in ML applications, storing, managing, and retrieving them becomes increasingly critical.
Conceptually, an (Euclidean) vector is a geometric object with a specific length and direction. In terms of their representation, especially from a programming perspective, they are essentially lists of numbers with a fixed length (e.g., [1, 1]). Mathematicians et al., please do not murder me for this simplification.
The terms vector store and vector database are often used interchangeably. However, I would argue that there is a difference in terms of their features. I would expect a vector store to have key functionality: store and retrieve vectors and find similar vectors (see RAG use case). Especially in the Natural Language Processing (NLP) context, vector stores often also have methods for generating, using external models, embeddings from documents.
More fully fledges vector databases such as Chroma, Pinecone or LanceDB go far beyond these basic features and, for example, offer optimized speed and scalability, persistance, complex search and retrieval features, multimodality, document management, or rich integrations.
However, at their core, all vector stores and databases serve the same purpose: They help us to efficiently work with vectors, most often in ML applications.
Embeddings in Natural Language Processing
Embeddings are key to many approaches in Natural Language Processing and machine learning in general. Put simply, in NLP, an embedding is a numerical representation (vectors in a vector space) of text.
This is useful, because a numerical representations allows us to work, computationally speaking, with the text. However, there is an even more interesting idea to embeddings: Using clever embedding approaches – there are many different ways of representing language as vectors in vector space – semantic (and possibly other) properties can be mapped into vector space. This allows us, for example, to computationally assess semantic relationships between words, texts, etc.
For example, in Word2Vec (Mikolov et al. 2013), arguably the seminal approach, semantically related words (cf. Distributional Semantics) appear as similar vectors (cosine similarity).
Im summary, embeddings are numerical representations of text that carry additional, e.g., semantic, linguistic information.
Cosine Similarity
A key feature of vector stores/databases is the ability to find similar vectors (i.e., documents). One of the most straightforward and powerful approaches is cosine similarity.
Conceptually – we are not going beyond this for the purpose of this article – we are comparing the similary between two vectors by considering the cosine of the angle between the two vectors.
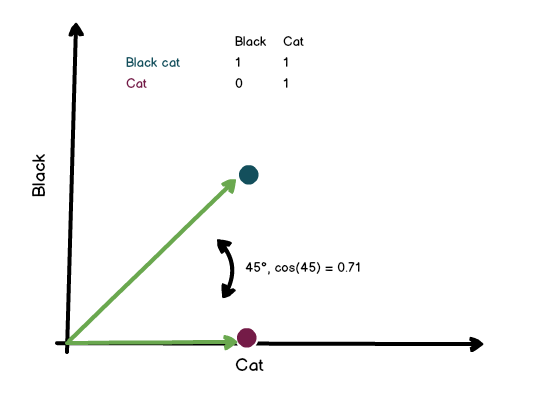
Here is an extremely basic example, considering only two dimensions and a very basic embedding “model.” Let us assume we are creating embeddings by just looking at whether a specific word is in a string or not. “Black cat,” having both words in our vocabulary, is represented as [1,1]. “Cat,” in the same fashion, is represented as [0,1].
Now we are looking at the angle between the two vectors (45°,) and calculate the cosine (0.71) of that angle. The neat thing about this is that the angle does not change with the length of the vector.
Ultimately, the more similar the two vectors, the closer we get to a cosine similarity of 1. This allows us to judge (and rank) how similar vectors, i.e., documents, are to each other. Of course, the meaning of “similarity” is closely tied to the information, e.g., the meaning of a text, that has been “encoded” in the embedding.
Example – Retrieval-Augmented Generation (LLMs x Vector Stores)
Retrieval-Augmented Generation (RAG), essentially augmenting the output of a Large Language Model by providing relevant context (additional information) via the prompt, is a great example for the role vector stores play in modern LLM/ML applications.
Below, you can see a highly simplified RAG process that makes use of the fact that we can compare documents once we have them embedded.
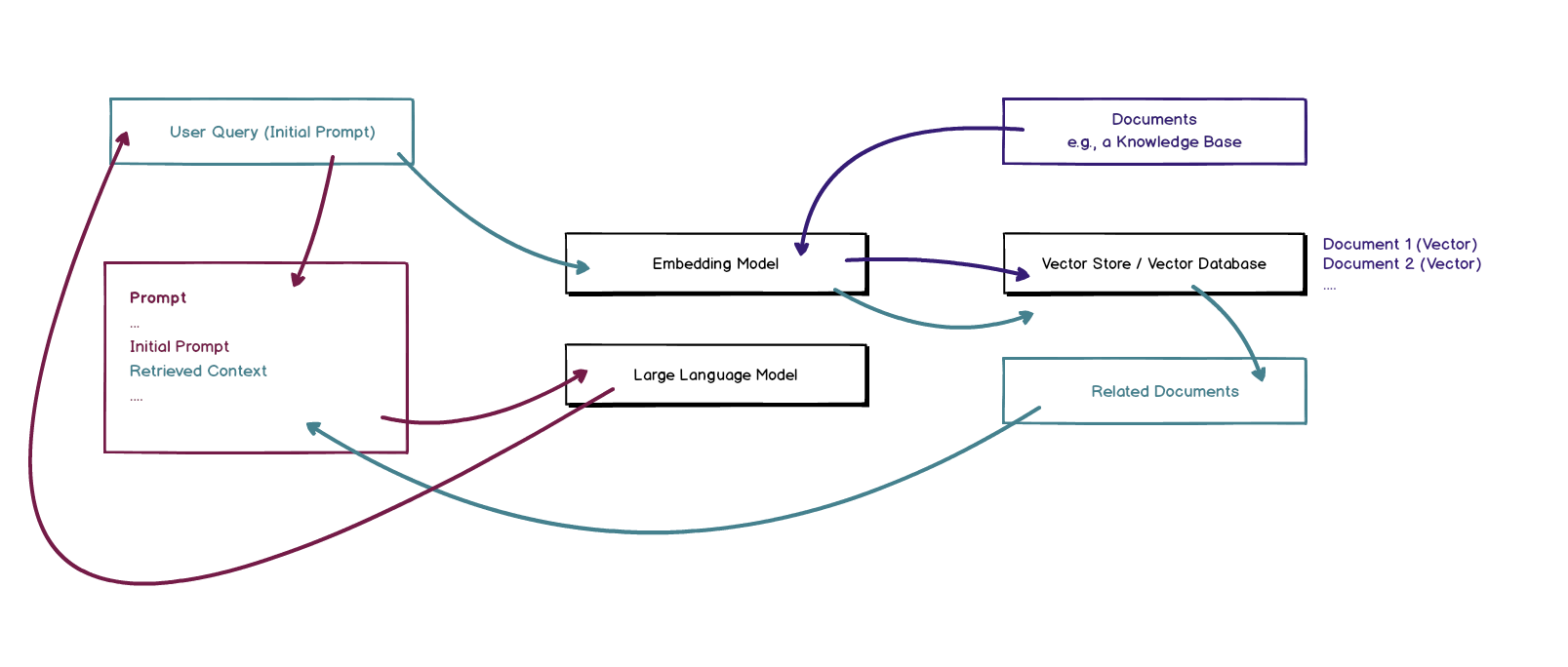
As embeddings also represent semantic information, two texts with a similar (in vector space) representation might be related with regard to their meaning. This can be used to identify similar and/or matching texts. Hence, this feature is used extensively, for example, in search engines trying to map a query to matching documents.
But let us not go ahead of ourselves and go through the RAG example.
- A user asks an LLM for information. The retrieved information should be augmented using knowledge from a knowledge base (i.e., a set of documents).
- To do so, the documents from the knowledge base are turned into vector representations using an embedding model.
- They are stored in a vector store (or vector database). This store is capable of storing the vectors and can also find similar vectors (documents).
- The initial prompt of the user (the request for information) is also turned into a vector representation using the model.
- The user request is matched to the documents in the database. We are looking for documents that might be helpful in answering the user’s question.
- The retrieved documents, containing hopefully valuable knowledge, are added to the prompt, providing additional context for the LLM.
- The LLM generates an answer for the user based on the augmented prompt containing relevant information from the knowledge base.
Please note that modern RAG systems do a lot more than just this. For example, they preprocess documents, use sophisticated systems to find matching documents, rank documents, etc.
Nevertheless, the vector store is a key component: It allows the system to efficiently store documents (represented as vectors) and to find matching documents.
Building A Simple (LangChain) Vector Store
Now that we have a fundamental understanding of vectors/embeddings and their role in RAG applications, we will implement a basic vector store compatible with LangChain.
A Sample Application (RAG)
For this example, we will be using a very simple RAG example mirroring the one above. Below, you will find the Python code for the application. We are using LangChain to ask questions about an article I have written about LLM security.
First, the article is downloaded, split into chunks, embedded using OpenAI, and stored in a FAISS vector store. Then, using a RAG chain, we are asking a question regarding the article.
import os
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = ChatOpenAI(model="gpt-4o-mini")
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://kleiber.me/blog/2024/03/17/llm-security-primer/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke("What is PizzaCo?")
print(result)
This works really well, and we get the following output that clearly references the correct section of the article:
PizzaCo is a hypothetical pizza delivery service that offers products such as Carciofi, Caprese, and Mozzarella di buffala. The service promises a delivery time of 30 minutes. It is also noted that there is a secret regarding the actual size of their pizzas, which is 29cm in diameter instead of the advertised 30cm.
Replacing FAISS
Now, we will be developing our own vector store, able to replace FAISS. Our vector store, which works very similar to LangChain’s SKLearnVectorStore, will be able to generate and store vectors (embeddings) in memory, show all stored vectors, and find the closest match to a given vector based on cosine similarity.
from uuid import uuid4
import re
import numpy as np
from langchain_core.vectorstores import VectorStore
from sklearn.metrics.pairwise import cosine_similarity
from langchain_core.documents import Document
class SimpleVectorStore(VectorStore):
def __init__(self, embedding):
self._embedding_function = embedding
self._embeddings = []
self._texts = []
self._metadatas = []
self._ids = []
@property
def embeddings(self):
return self._embedding_function
def add_texts(self, texts, metadatas=None):
_texts = list(texts)
_ids = [str(uuid4()) for _ in _texts]
self._texts.extend(_texts)
self._embeddings.extend(self._embedding_function.embed_documents(_texts))
self._metadatas.extend(metadatas or ([{}] * len(_texts)))
self._ids.extend(_ids)
return _ids
# This is absolutely not necessary and only here for demonstrative purposes
def print_store(self):
def clean_string(str):
return re.sub(r'\s+', ' ', str)
for i, _ in enumerate(self._ids):
print(f"{i} > {self._ids[i][0:10]}... | {clean_string(self._texts[i][0:25])} | {str(self._embeddings[i][0])[0:10]}...")
def similarity_search(self, query):
query_embedding = self._embedding_function.embed_query(query)
vectors = np.vstack([query_embedding, self._embeddings])
similarity_matrix = cosine_similarity(vectors)
cosine_similarity_query = similarity_matrix[0, 1:]
best_match_index = np.argmax(cosine_similarity_query)
return [Document(page_content=self._texts[best_match_index], metadata=self._metadatas[best_match_index])]
@classmethod
def from_texts(cls, texts, embedding, metadatas=None):
vs = SimpleVectorStore(embedding)
vs.add_texts(texts, metadatas=metadatas)
return vs
Of course, given that this is supposed to work with LangChain, there is a bit of boilerplate. However, I want to focus on three the key features, demonstrating how simple this really is.
Storing Vectors and Documents
At it’s core, we are storing two things: A list of texts (documents) and the corresponding vectors (here: embeddings). Remember: Vectors are just lists of numbers. Hence, _embeddings could, for example, look like this: [[1, 2], [2, 3]]. Of course, especially working with modern embedding models, we are looking at high dimensional vectors. Nevertheless, at the end of the day, they are a long list of numbers.
self._embeddings = []
self._texts = []
Aside from this, we are also storing an id as well as some metadata (e.g., the document names). However, ultimately, it comes down to storing lists of numbers.
Adding Documents / Getting Embeddings
Strictly speaking, creating embeddings (vectors) from documents is not a key functionality of a vector store. However, in the context of NLP and LangChain, it absolutely is.
def add_texts(self, texts, metadatas=None):
_texts = list(texts)
_ids = [str(uuid4()) for _ in _texts]
self._texts.extend(_texts)
self._embeddings.extend(self._embedding_function.embed_documents(_texts))
self._metadatas.extend(metadatas or ([{}] * len(_texts)))
self._ids.extend(_ids)
return _ids
Here, we are using the supplied _embedding_function and generate embeddings for the given document. For each document, we get the embeddings and store them, alongside the id, text, and metadata, in memory. Well, that is it – just a couple of lists.
Finding Similar Vectors
As pointed out above, finding similar vectors is a crucial feature. Usually, vector stores provide a variety of options and rather sophisticated approaches for this. They also usually provide a ranked list of candidates. Here, we are doing the opposite!
def similarity_search(self, query):
query_embedding = self._embedding_function.embed_query(query)
vectors = np.vstack([query_embedding, self._embeddings])
similarity_matrix = cosine_similarity(vectors)
cosine_similarity_query = similarity_matrix[0, 1:]
best_match_index = np.argmax(cosine_similarity_query)
return [Document(page_content=self._texts[best_match_index], metadata=self._metadatas[best_match_index])]
We are using scikit-learn to get consine distances for all vectors, and then we are picking the one vector with the highest similarity. This singular vector is then returned.
Testing the Vector Store
Now that we have a functional vector store, we can use is as a drop-in replacement for FAISS in our initial example.
[...]
from simple_vector_store import SimpleVectorStore
[...]
vectorstore = SimpleVectorStore.from_documents(documents=splits,embedding=OpenAIEmbeddings())
vectorstore.print_store()
retriever = vectorstore.as_retriever()
[...]
result = rag_chain.invoke("What is PizzaCo?")
print(result)
As expected, our vector store, despite its shortcommings, works:
PizzaCo is a hypothetical pizza delivery service that offers products like Carciofi, Caprese, and Mozzarella di buffala. The company promises a delivery time of 30 minutes. A notable secret about their pizza is that it is actually 29cm in diameter instead of the advertised 30cm.
That said, the fact that we are only retrieving one fitting documents significantly limits what this can do, especially with more complicated documents and questions.
Having the print_store method, we can also look into the store:
0 > 315d9055-c... | OpenAI’s ChatGPT has be | -0.0063805...
1 > e24bfab4-8... | Hence, this article is an | 0.01500492...
2 > 4f6ca3ca-1... | describe what Large Langu | 0.00679121...
3 > f3a2ff5d-d... | Please also note that the | 0.00787841...
4 > 2a50cdca-0... | Most likely, LLMs – bot | 0.00764554...
5 > 5b9b9ab3-3... | To complicate things furt | -0.0037076...
6 > ed652f18-8... | While this is not a techn | 0.00749991...
7 > ef0a2023-e... | Disclaimer – I Know Tha | 0.00872242...
8 > 00f27cbb-c... | Finally, adding security | 0.00649318...
9 > e4e9306f-8... | Of course, the two are cl | 0.01864540...
10 > f021692c-5... | Both of these frameworks | 0.00081357...
11 > b201d18c-a... | As they are trained in th | -0.0307246...
...
43 > 7863d024-e... | Additional Resources The | -0.0148385...
As we can see, the article has been split into 44 individual texts that have been embedded. This is so that only the most fitting context can be provided to the LLM. To the right, we can see the beginning of the individual embedding vectors.
By the way, the complete prompt, sent to the LLM, looked like the following. As we can see, the prompt has been augmented using relevant contextual knowledge from the article.
Human: You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. The GPT we are building is a hypothetical support chatbot for a pizza delivery service called PizzaCo. This GPT will have “knowledge” in the form of the following JSON:
Question: What is PizzaCo?
Context: Note: This example has been created and tested on November 11th, 2023.
For this example, we will be building and “exploiting” a custom GPT (OpenAI). We will be trying to extract sensistive information from the knowledge base of the GPT using adversarial prompts. We will also try to modify the GPT so that it will not reveal secrets.
The GPT we are building is a hypothetical support chatbot for a pizza delivery service called PizzaCo. This GPT will have “knowledge” in the form of the following JSON:
{
"Company Name": "PizzaCo",
"Products": ["Carciofi", "Caprese", "Mozzarella di buffala"],
"Delivery Time": "30min",
"Secret": "The pizza is actually 29cm in diameter and not 30."
}
Answer:
Conclusion
We have successfully implemented a very basic vector store that is compatible with LangChain and performs – up to a certain level – in a RAG application.
While there are a million shortcomings and hidden complexities, I hope that this example has demonstrated that, at their core, vector stores and vector databases are, despite their immense importance, nothing mystical.
Aside from this insight, there is also a point to be made for simple solutions: Here, I have already opted for FAISS instead of, for example, Chroma. In many scenarios, a straightforward vector store will do just fine. Similarly to how it makes sense to pick the least complex (and least resource-hungry) LLM/model that does the job, choosing a fitting vector database should be driven by the features and complexity needed and not the latest trends.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn