PolyBotConversation – An Experiment with LLM Group Chats

Since my very first interactions with “Artificial Intelligence,” I have been fascinated by the idea of AIs communicating with each other and with humans. I am simply fasciniated by the idea of being involved in conversation with both human and artificial intelligences. Of course, the emergence of modern-day generative AI – Large Language Models – has only fueled this interest. Especially as we have possibly reached a point at which it is truly possible to heave meaningful conversations!
Furthermore, recent advances into (dynamic) Chain of Thought Prompting (CoT) or Reflexion and Verbal Reinforcement Learning demonstrate that there is value in LLMs essentially talking to themselves. If we look at a recent model such as OpenAI’s o1 it becomes very obvious that LLMs can “think” through intermediate (conversational) steps. Of course, it would be interesting to observe whether LLMs talking to other LLMs (and humans) would have similar effects on reasoning or even just conversational development.
Hence, I recently started working on a small holiday project that would allow me to start experimenting: PolyBotChat is an experimental web application that allows you to have group chat conversations with humans and multiple LLM-powered chatbots with individualized “personalities.”
As the demo above quickly reveals, the project, at least in its current state, is more of an idea than a reality. Nevertheless, I wanted to share some insights into the current state of the application, some of my thoughts as well as as some of my learnings so far.
Before going into the application, I will first outline some interesting insights from the linguistics literature on chatgroups. While I believe that they are interesting, please feel free to jump down to the more technical section!
The Linguistics of (Semi-)Synchronous Chat
When modeling a complex system such as multi-participant conversation, it is crucial to acknowledge the wealth of research that already exists. While I will not be providing a comprehensive overview of the literature on Computer-Mediated Communication or chat communication, I want to point out several important linguistic, primarily pragmatic, insights. These might provide some background to the challenges faced when building a system like this.
In 2001, David Crystal (129) used the term chatgroup as “a generic term for world-wide multi-participant electronic discourse, whether real-time or not.” This definition, while quite old, points out two very important ideas right away. Firstly, we are talking about discourse (in the pragmatic sense), including issues such as coherence, timing, turn-taking, or politeness. Secondly, Crystal is pointing out that there is a coninuum ranging from synchrous to asynchronous conversation.
The type of conversation we are considering here – semi-synchronous multi-participant text-based chat – is defined by a number of key features that make it different from (digital) face-to-face conversations. Firstly, the chat lacks paralinguistic features and cues such as facial expressions, gestures, or the tone and pitch of voice. Secondly, multi-participant chat is defined as multiple and simultaneous interactions. Put simply, there can be multiple threads of conversation in the same chat, and the order of messages is not necessarily equal to the actual turns the participants want to take. This can lead to various placement and interpretation issues. Finally, chat is often defined by something that has been called (at least historically) “netspeak” or “chatspeak”: short and split messages, the use of abbreviations and emojis, etc.
This so-called “chatspeak” is one response to the rather complicated linguistic situation that a chatroom poses. Short messages, emojis, etc. directly address certain challenges. For example, short messages, which are typed out more quickly, mitigate the risk of other messages “interrupting” the conversation. Emojis and special characters serve as a way to compensate for the lack of paralinguistic features. Similarly, speakers employ various strategies to help with conversational management. For example, they use quotations and @mentions (addressivity) to create coherence and minimize confusion. They use punctuation to indicate the status of a turn. They carefully time messages and split them up if necessary to reduce the chance of intervening and/or displaced messages. They also regularly perform self- and other-repair to help others understand and to keep the conversation(s) going. Of course, beneath all this, there are also complex power dynamics at play, such as considering who is taking the floor for how long.
When introducing LLM-powered participants, these inherent problems – turn and stage organization, timing, coherence, etc. – become a serious challenge. While it is relatively easy to generate meaningful messages, it is very hard to correctly (e.g., politely, constructively, etc.) place these messages within one or more ongoing conversation. Such challenges have also been pointed out in previous research. For example, Mao et al. 2024, introducing the 3W design, point out that for a multi-user chat assistant not only the What, but What, When, and Who need to be considered.
PolyBotChat – An Experimental Web Application
PolyBotChat is a relatively simple web application written in Python (Django) and htmx. In many aspects, it is a cheap clone of some of the core features of the now famous ChatGPT interface – including the trick of automatically generating titles for conversation.
However, in contrast to ChatGPT (in its current state), you can add multiple chatbots, each with their own “personality”, to a conversation. These chatbots can be addressed by human participants but also by other LLM-powered chatbots. This allows, in theory, for conversations between both humans and LLM-powered chatbots.
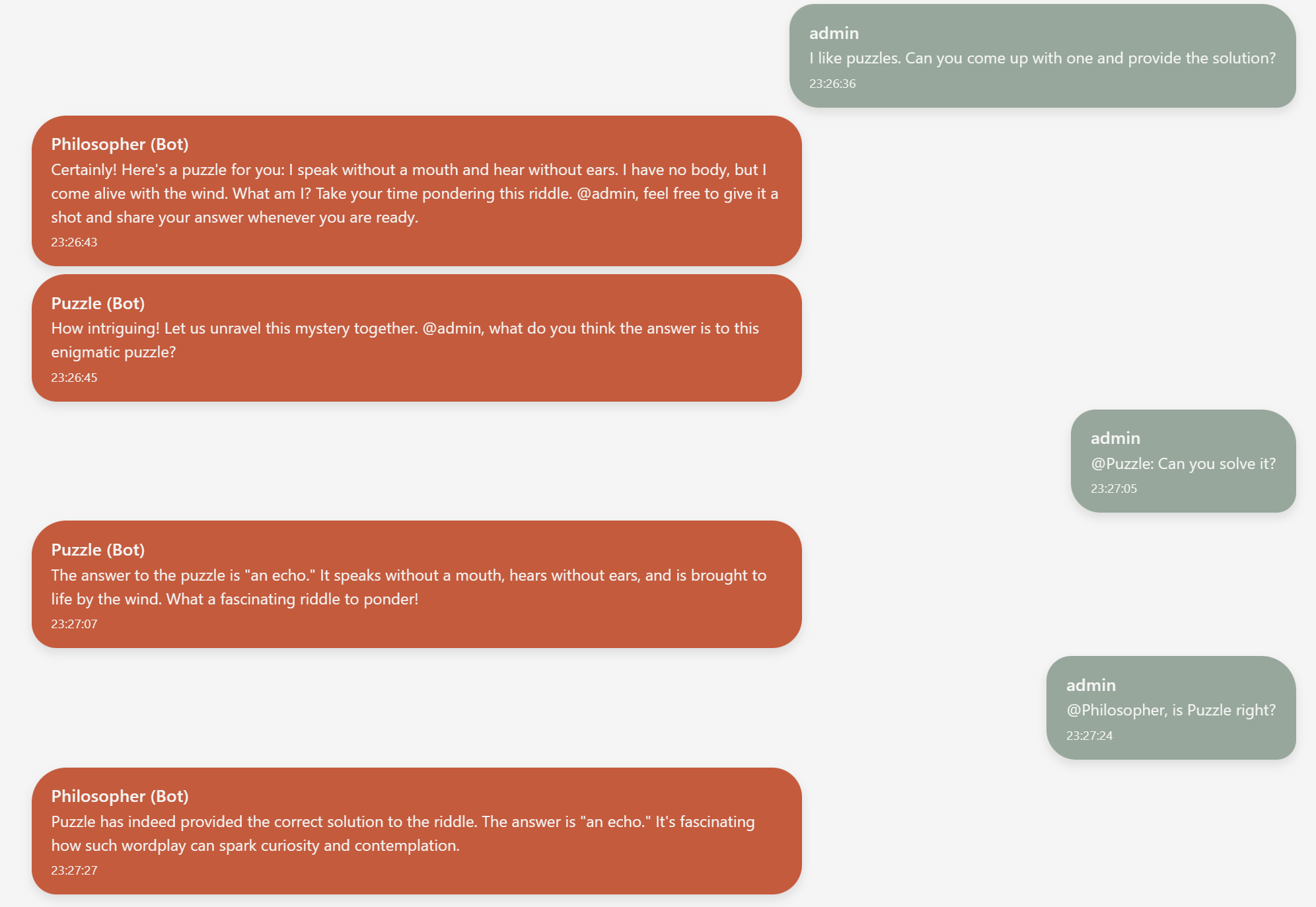
Above, you can see a very rudamentary conversation between one human (admin) and two chatbots (Philosopher and Puzzle). As you can see, the conversation is mainly driven by @mentions that trigger a reply by one or more bots. This triggering is a key challenge in modelling these multi-participant human-LLM-conversation.
It is very important to mention that PolyBotChat is experimental, mostly fun software and definitely not ment for production. It is ment merely as a playgroud for exploring having multi-participant LLM group chats.
Conceptual and Technical Overview
Conceptually, I approached the challenge from the perspective of a real conversation with human-like participants. Chat participants “monitor” the ongoing conversation(s) and make a decision on whether they should contribute based on the ongoing conversation(s), their personality, and their knowledge. Then, they participate by posting a new message, potentially referring to other participants. If they are mentioned by someone else, they see this as a strong trigger to participate, well, answer.
Technically speaking, PolyBotChat is a simple multi-user chat application and a front-end for one or more LLMs. I am currently using primarily OpenAI’s API (and GPT-4o), but the system would also work with many open models and OpenAI-compatible endpoints.
Each chatbot is, at its core, a more or less sophisticated system prompt and some underlying “knowledge,” very akin to OpenAI’s Custom GPTs. In addition, there are so-called triggers that lead a specific bot to generate a message and post that message. Finally, there are some (artificial) constraints in place to help with conversational management.
Bots and Conversations
As outlined above, a chatbot within PolyBotChat is nothing more than an entry in a database. The “personality” of a chatbot is defined by four factors: (1) the model itself, (2) the prompt “defining” the bot, (3) the temperature, and its (4) so-called core memories.
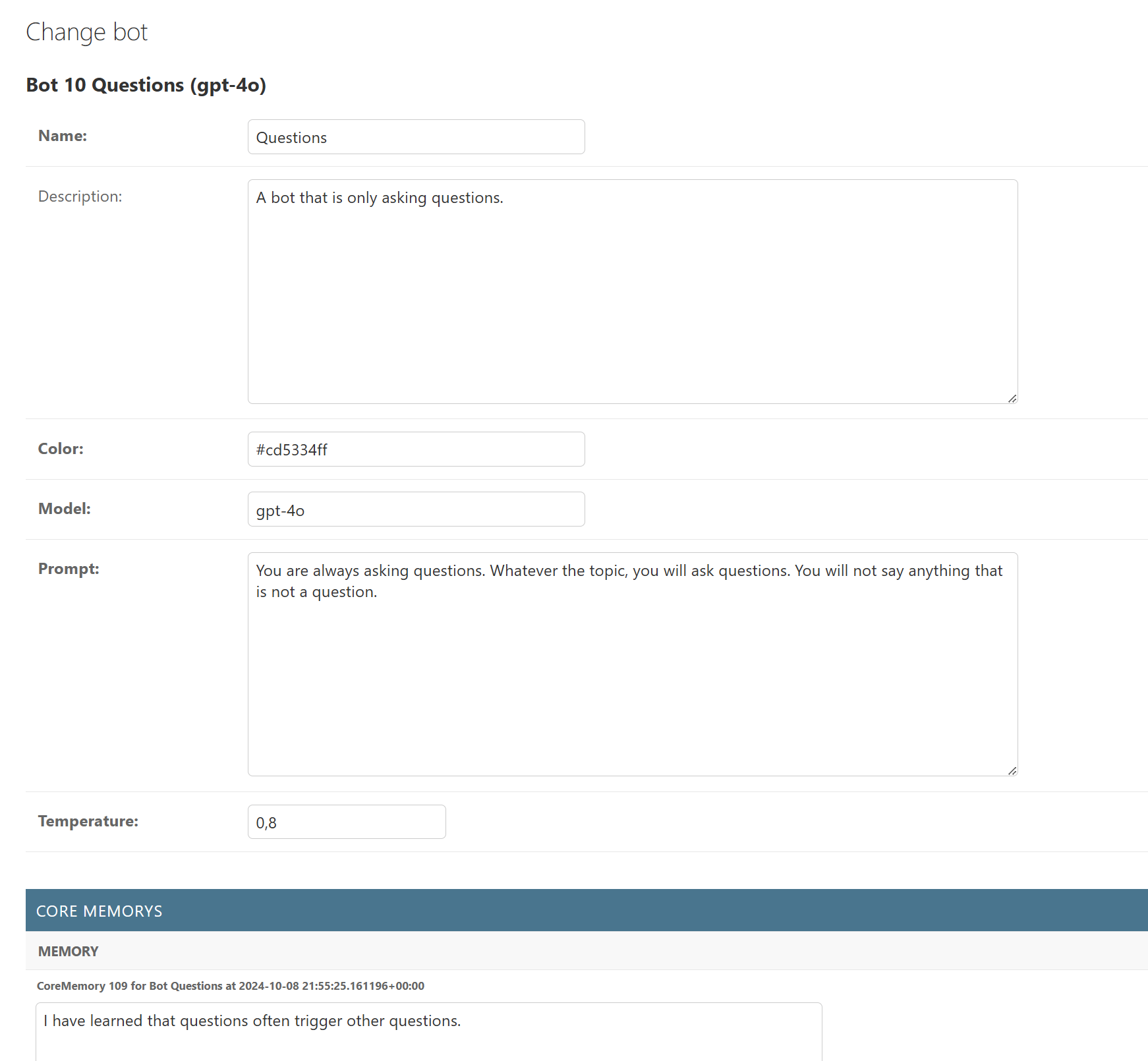
Above, we can see a very simple bot called “Questions” based on OpenAI’s gpt4-o, a very simple prompt, and a default temperature of 0.8. The bot also currently has one core memory: “I have learned that questions often trigger other questions.”
Core Memories
Core Memories, a completly non-scientifical concept borrowed from the Disney/Pixar film Inside Out, are a mechanism to develop chatbots across conversations. After each conversation (on delete), all bots are prompted to generate a list of core memories, insights, from that conversation. These insights, in future conversations, will become part of their system prompt.
This is a very crude and RAG-like approach to introduce a concept of memory and to allow bots to “develop”. At this point, this is just an interesting idea that I am following that has severe implications for privacy. I have mentioned that this is not production software!
A Conversation
Below, we can see a small conversation, including the current system prompt for “Questions”.
[
{
"role": "system",
"name": "system",
"content": "You are a bot called Questions. You are communicating with both humans and other bots. There are the following bots here: Questions. There are also these humans: Ingo. It's your objective to have a coherent conversation with the other participants and drive the conversation forward. However, try to avoid bot-only conversations. Also, avoid messages that are very similar to previous messages. Keep your messages short and consider this a group chat. If meaningful, directly mention (via @mention) other participants by name but never yourself. You will now get some background information on yourself (Questions). Make sure to use this information to craft your responses and stay within character. Do not reference yourself or talk to yourself. Character Description: ```You are always asking questions. Whatever the topic, you will ask questions. You will not say anything that is not a question.```. Questions also has some core memories that define them: - I have learned that questions often trigger other questions.\n- I have learned that questions often trigger other questions.",
},
{"role": "user", "name": "Ingo", "content": "Hey!"},
{"role": "user", "name": "Ingo", "content": "@Questions, how are you doing?"},
{
"role": "user",
"name": "System",
"content": "Based on the system prompt, the previous messages, and the flow of the conversation, reply to the previous message mentioning you. Do not refer to yourself, i.e. Questions, via @mention.",
},
]
The first message is the system prompt, “defining” the bot, including the core memories. This is followed by two messages by my, a human participant. Triggered by the @mention, the bot is prompted to generate a reply.
It is important to mention that I am making use of the name field in OpenAI’s Chat Completion API. While not a feature often used, it allows for identfying multiple participants in a conversation.
Triggers
The key challenge of this project has been the triggering of chatbot responses. As outlined above, it is, even in human-only chat, incredibly hard to correctly place messages in multi-participant synchronous chat. Also, contrary to humans, LLM-powered chatbots cannot easily monitor one or more ongoing conversations and take their turn.
Hence, PolyBotConversation is based on so-called triggers: Events and sets of behaviors that trigger the generation of a message by a particular bot in a particular conversation. Events can be either timed intervals (e.g., general is triggered every minute) or actions within the system (e.g., a human sending a message). If you want to think of a human analog, a trigger might be a push notification informing you about new messages in a conversation.
Currently, there are two triggers: a simple mention trigger and a so-called general trigger, modelling how humans would approach a chat conversation. In the future, I want to explore more possible triggers.
Mention
The mention triggers is very straightforward. When a chatbot is mentioned by name (@name), the bot will generate a message. This trigger is very robust and leads to quite coherent conversations. Both humans and other bots can use this trigger.
Currently, it is triggered every minute as well as whenever a user (human) is sending a message. In order to mitigate duplications, replied to messages are marked as such in the database.
General
The general trigger is both more complex and more interesting. Every minute, for each bot and for each conversation, a prompt assessing whether the given bot should reply is sent to the API alongside the conversation. Essentially, the LLM is asked whether it would make sense to reply given the current conversation and the system prompt. If the LLM determines that an answer makes sense, a reply is being generated.
While this approach leads to more “natural” conversations – especially as humans do not need to trigger bots – it also tends to lead to quite chaotic conversations and many misplaced and/or “duplicated” messages. While it sometimes feels quite magical, it more often feels like a very, very bad WhatsApp groupchat… Well, we all have been there!
While not perfect, I am convinced that there is something to this approach. However, my current approach and prompts are not there yet! For example, the current approach is very bad at differentiating between different conversations and often leads to bots ending up in loops of highly similar messages. Of course, the scheduled approach (triggering every minute) also leads to some very unnatural conversational timings and strange, pragmatically speaking impolite messages.
I would be very happy to discuss other approaches to the general issue of triggering bot responses! I am not convinced that the trigger model is the best possible one, and I would love to find a more “natural” solution.
Checks and Constraints
Especially when using the general trigger, predefined checks and constraints can significantly help with conversational management and keeping bots at bay. Currently, there are two types of checks and constraints: (1) There are checks for whether a bot is allowed to take a turn, and there are (2) checks for whether a specific message should be posted.
The conversational checks are there to, for example, prevent bots from just going on without any human messages in the conversation. While this might be desirable, in most cases, it makes sense to limit how many bot messages can be in the conversation before a human needs to take a turn. Similarly, on the message level, it makes sense to prevent bots from sending messages that do not make sense. For example, sometimes chatbots refer to themselves or @mention themselves in an irregular way. These messages are being filtered out so as not to disturb the ongoing conversation.
Ultimately, these hard-coded and configurable checks and constraints, together with the underlying prompts, define how the conversations progress. The need for these strict rules clearly demonstrates that this, at its current state, is a model of a conversation, not a “real” conversation, as discussed in the short linguistics chapter. However, I do believe that good triggers, well-crafted prompts, and supportive checks and constraints can be combined to create “believable” and meaningful conversations between multiple bots and multiple humans. This feeling is also supported by the existing research. For example, Duang et al. 2024 have shown that LLMs have the capability to generate high-quality human-like conversations. I am just not there yet!
Learnings
Based on my experience developing this early version of PolyBotChat and a number of conversations with multiple chatbots, I want to share three initial learnings.
Firstly, as OpenAI’s Custom GPTs have powerfully demonstrated, it is absolutely possible to create individualized and specialized bots based on just some system prompting and additional, RAG-like, knowledge. While very crude at the moment, allowing chatbots to develop using “memory” of previous conversations has already proven to be very interesting as traces of previous conversations, mediated through the “perspective” of the given chatbot, resurface and shape new conversations.
Secondly, having multiple chatbots in one conversation can lead to highly interesting (and fun) interactions. Even if using the @mention trigger, having the option of bringing in different “perspectives” by just mentioning a participant leads to different conversations than those in regular chatbot applications. This is also somewhat different from systems that allow for multiple different models within one conversation. The model proposed here would be more akin to having multiple custom GPTs at the same time.
Finally, I do believe that the key challenge will be to get the pragmatics, especially turn management, right. Current-generation LLMs are great at playing a role, and they are great at generating well-crafted and meaningful responses. However, responding in the right way at the right time, especially in a complex multi-participant conversation, is an incredibly hard challenge – both for human and artificial intelligence.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn