A Short Primer on LLM Routing

A couple of days ago, OpenAI launched GPT-5 to the public. Doing so, OpenAI did not just launch new models, but also mainstreamed LLM routing.
Instead of choosing a model to use, there now is “a real‑time router that quickly decides which [model] to use based on conversation type, complexity, tool needs, and your explicit intent” OpenAI. This router, which decides whether you get the fast and cheap version of GPT-5 or the reasoning variant, “is continuously trained on real signals”.
Put simply, when using GPT-5, there is a trained system that considers your input and decides, on the fly, which model will be best for you; or at least, which model will be picked for you. This, in essence, explains the idea of LLM routers. Of course, this is not a new concept and many AI systems, including ChatGPT, have been making use of it, e.g., when routing to an image generation model, for a long time. Nevertheless, with GPT-5, the both loved and hated model picker, at least for most users, has disapeared.
This article serves as a primer for those interested in routing. Therefore, ín the following, we will be looking at some fundamentals, how these systems, on a high level, work, as well as both benefits and challenges of using them. Please don’t expect a deep dive into specific routing approaches and be prepared for some gross oversimplifications!
If you have a good understanding of how LLMs work, especially their statelessness, feel free to skip the following fundamentals.
Fundamentals
LLMs, in general, are stateless, which means that the model itself does not remember anything from one interaction to the next unless that information is provided again in the input. Hence, there is no inherent concept of a “conversation,” and in order to have one, all previous messages have to be sent in the next request. This means that LLM routing is relatively easy as for each request, a different model could be chosen. This also allows us to change models mid-conversation.
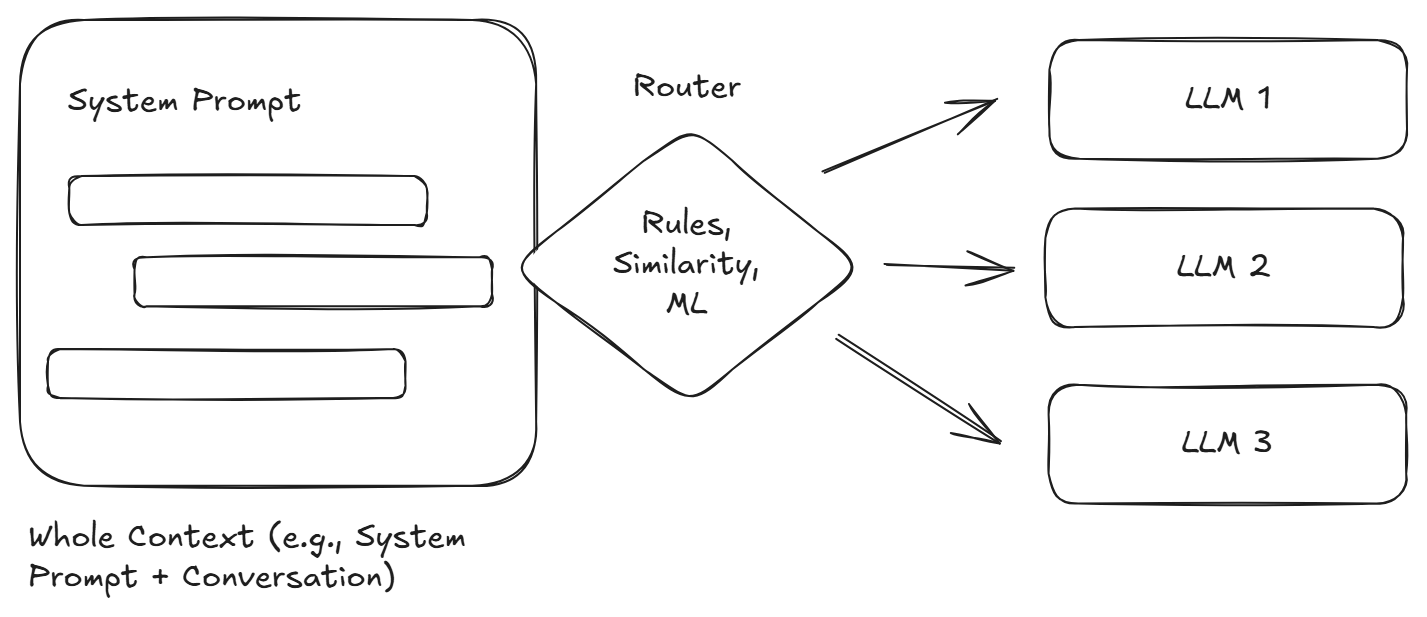
LLMs also vastly differ in their capabilities and requirements. For example, there are powerful reasoning models that require extensive compute and generate thousands of tokens during reasoning as well as extremely small and efficient models that, despite their size, are still capable of solving certain tasks. Of course, based on their training, some models are also better geared towards certain tasks and domains. Hence, choosing a fitting model is important.
There are two related concepts that are often confused with LLM routers: Unifying Gateways and Mixture-of-Experts (MoE) models.
There is a growing number of services that provide a unified gateway to many proprietary and open models (e.g., OpenRouter or LiteLLM). While some of them, e.g., OpenRouter via Not Diamond, provide intelligent routing functionality, their primary features include providing a unified interface to many LLMs, simplifying access and accounting, providing fallbacks, and advanced analytics.
Mixture-of-Expert models follow a similar approach to LLM routing. However, instead of choosing between multiple models, there are multiple so-called experts within one single model. Going into the details of MoE is outside the scope of this article, but you can essentially imagine that tasks are routed inside the model to one or a few expert subnetworks.
Put simply, LLM routing refers to routing a request, on a systems level, to one of many LLMs. In comparison, in the MoE-case, the routing happens on the network level within one singular model containing multiple experts.
LLM Routers
By now, there are thousands of LLMs available – big and small, closed source and open source, non-reasoning vs. reasoning, general and specialized etc. Therefore, and also because the inference cost of state-of-the-art (reasoning) models can be substantial, picking the right model for a given task is now commonplace. The days in which we simply picked the best available model and ran with it are over. Instead, we carefully deliberate which model, for example, considering capabilities, cost, sustainability, safety, computational requirements, or licensing to use for a given task.
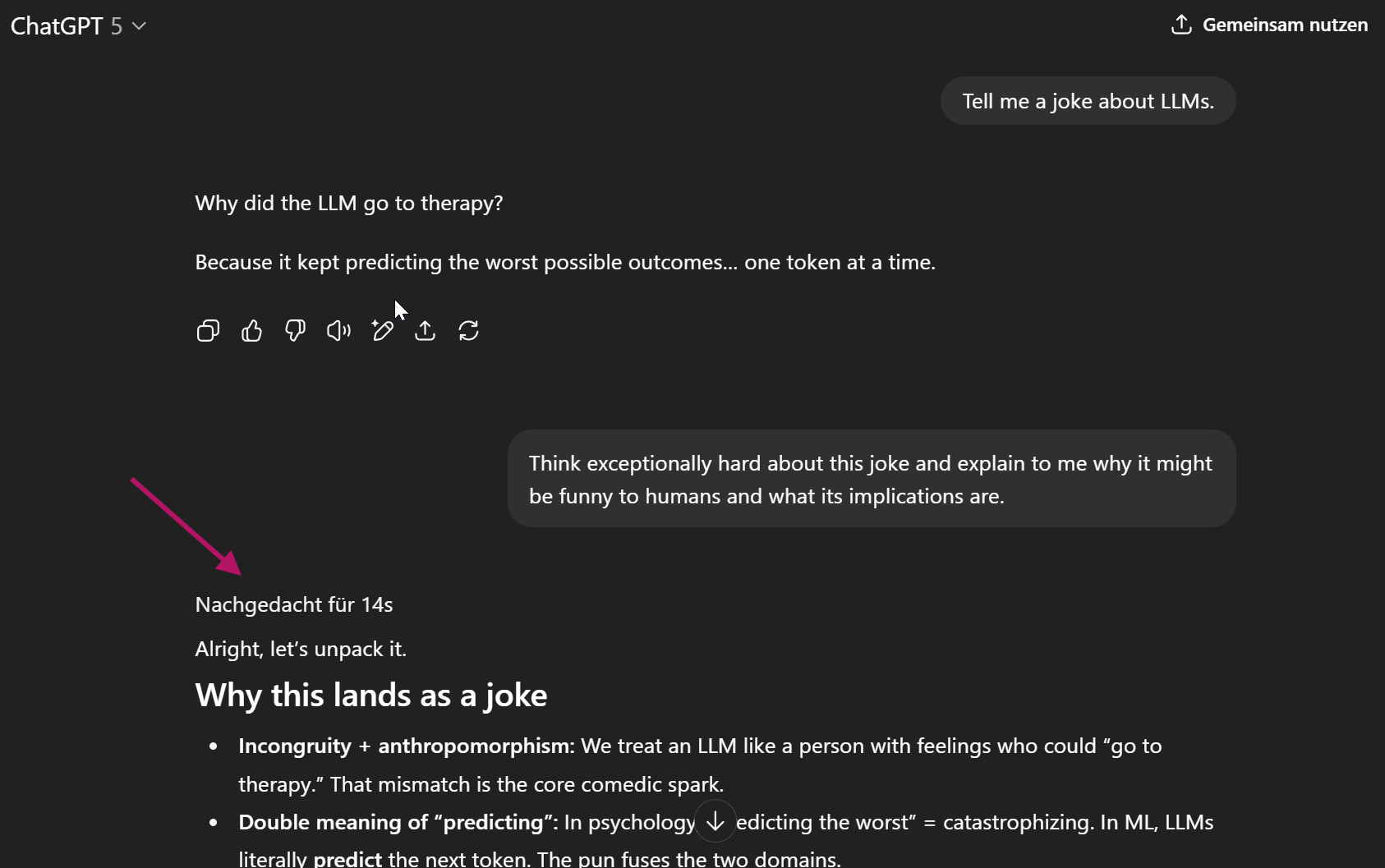
In this example from August 2025, ChatGPT, its router, decided to use the reasoning variant of GPT-5 for the second user message. There’s already an interesting decision here: OpenAI’s router seems to make decisions for each new message. This is a fundamental decision in conversation use-cases: Are we deciding on a model for the whole conversation or each individual message? What we don’t know, at least I don’t, is how ChatGPT handles the previous messages, i.e., if on a model change the whole previous conversation is routed to the new model.
Usually, we want to route a single request – a prompt – to an available (LLM routers also can do some load-balancing) and fitting model.
Approaches to Routing
There are many approaches to LLM routing. Certainly missing a few key ones, here are some of the most common approaches. Definitely check out awesome-ai-model-routing for further information.
Load-Balancing
The simplest approach does not regard content and is only concerned with model availability. Essentially, we are talking about a load balancer that routes the request to an available model. Here, all of the common load-balancing approaches, such as round robin, might be used.
Rule-Based Routing
Rule-based routers pick the model based on a set of predefined rules. These could include the length of a prompt, the linguistic complexity of a prompt, certain keywords, etc. In addition to these content-based rules, such as system could also route based on origin or metadata. For example, there could be a rule that sensitive data is always routed to a specific internal LLM.
def route_prompt(prompt: str):
if len(prompt.split()) > 100 or 'reason' in prompt.lower():
model = "Mistral Large 2"
else:
model = "Mistral Small 3.1"
return model
Above is a very simple example of what this could look like. In this toy example, if the prompt is longer than 100 words or contains the keyword “reason”, the larger, more capable model is chosen.
Semantic Routing / Embedding-Based Routing
For this approach, we are relying on a database of previous prompts and ideal models (e.g., based on benchmarks). New requests are then compared to previous prompts using embeddings (similar to a retrieval system) +, and based on previous experience, a model is chosen. A powerful example, going beyond just LLM routing, is aurelio AI’s semantic router.
ML-Based Routing
Here, a machine learning classifier is trained to select fitting models based on prior experience and selected features. For example, Not Diamond published “Routing on Random Forests”, a router that can very effectively select between two models.
The ML-based approach is becoming the most widely adopted one and there are hundreds of approaches, models, and developments. At the end of the day, the idea is that we leverage machine learning to find an optimal solution for a complex problem: finding, given many parameters, the best model for a given prompt or task in a very short period of time.
Opportunities and Challenges
Independent of the chosen approach, LLM routing has many benefits. Especially for less experienced users, a routing system can lead them to the model best suited for their tasks. In addition, they can save resources and help with compliance. Of course, they can also be very valuable in agentic use cases, when depending on the task, the tools, etc.,different models might be needed.
All of that said, routers, as is the case with GPT-5, can also be a pain, especially for power users. They reduce the predictability of AI systems even more: Users not only have to deal with the probabilistic nature of the models themselves, but also have to take into account that they might be routed to a different model altogether.
Conclusion
LLM routing, via OpenAI’s GPT-5, has now entered the mainstream and the consciousness of many users. At its core, it’s a simple concept: If there are many different models, it makes sense to build a system that picks the best one for a given scenario. As LLMs are stateless, this can be done for every single prompt.
While the approach has many benefits, e.g., saving valuable resources, it can introduce a new layer of uncertainty and unpredictability. Nevertheless, especially looking at end-user products, I would expect models to become more and more invisible. Clever routing, not only for the purpose of saving money (and the environment), will play a big part in providing a great user experience that’s tailored towards the specific tasks at hand.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn