A Basic Example for Format-Based Text Watermarking

Have you ever wondered if (and how) a text (in the sense of a string of characters) might be watermarked to verify its authenticity or origin?
The answer to this question is a set of approaches summarized under the heading of “text watermarking”. Ultimately, the goal is simple: We want to create or modify a text so that it contains an (invisible) watermark that can later be checked to verify the text, its integrity, authenticity, origin, etc.
Given the rise of LLMs and generative AI more broadly, this question has again become popular, as there is a growing need – or rather, a wish – to detect LLM-generated texts. The applications would be manifold: warning users about AI-generated content, combating fake news, fighting copyright infringements, detecting cheating in academic contexts, and distinguishing between AI- and human-generated texts.
On a personal note, I am torn. While I see the need to detect AI-generated content, I do not believe – despite cutting-edge approaches such as DeepMind’s SynthID – in the long-term success of technical AI detection. Furthermore, I agree with a 2024 Nature Editorial that strongly argues for robustness and the protection of content quality, especially from a legislative and adoption perspective.
As Liu et al. (2024) have shown, there are a series of very different approaches. They range from “simple” format-based approaches to training LLMs to output detectable patterns with a very low impact on text quality.
For a project, I recently had to implement a simple watermarking solution to add a watermark to existing text without changing the actual text/language. As this might be interesting, I wanted to share a simplified version of this approach here.
A Format-Based Approach
Format-based watermarking “changes the text format rather than its content to embed watermarks” (Liu et al. 2024). While they are easy to implement, they are also relatively easy to spot and to remove.
The basic approach I want to share as an example involves adding invisible characters to the text. This way, we can embed a literal watermark, as well as other information, into the text without altering its appearance for regular users. The approach is also relatively robust when it comes to copying and pasting watermarked text. That said, the watermark is easy to spot – even just by looking at the “file” size of the string – and can be removed easily.
On a high level, we are using two invisible characters, “\u200b” (Zero Width Space) and “\u200c” (Zero Width Non-Joiner) to encode information. Each of these characters will represent either 0 or 1, allowing us to encode and embed arbitrary binary information into the text.
For this implementation, we will be embedding a signature string, a timestamp, and a checksum to verify the watermark.
import hashlib
import time
from typing import Optional, Tuple, Dict
ZWS = "\u200b" # 0
ZWNJ = "\u200c" # 1
SIGNATURE_STR = "WATERMARK"
def _to_bits(s: str) -> str:
return "".join(f"{ord(ch):08b}" for ch in s)
def _from_bits(bits: str) -> str:
out = []
for i in range(0, len(bits) - (len(bits) % 8), 8):
out.append(chr(int(bits[i:i+8], 2)))
return "".join(out)
def _bits_to_zw(bits: str) -> str:
return "".join(ZWS if b == "0" else ZWNJ for b in bits)
def _zw_to_bits(text: str) -> str:
return "".join("0" if ch == ZWS else "1" for ch in text if ch in (ZWS, ZWNJ))
def _checksum4(signature: str, ts: str) -> str:
return hashlib.md5(f"{signature}:{ts}".encode()).hexdigest()[:4]
These utilities perform the encoding. For example, _to_bits will turn the string “Hi” into 0100100001101001.
Then, we can use _bits_to_zw to turn these bits (well, bytes) into \u200b\u200c\[...]\u200b\u200c.
Of course, this would allow us, at the cost of string length and size, to encode and embed as much information as we want. We also need to think about where to place the watermark within the text. For the following example, I opted to place the characters in the middle of the string to reduce the risk of losing them when copying and pasting.
That said, the _zw_to_bits implementation will try to piece together the bits in any case. Given this implementation, however, legitimate ZWS and ZWNJ will become a problem.
def encode(text: str, *, signature: str = SIGNATURE_STR) -> str:
"""
Insert an invisible watermark into the middle of `text`.
"""
if not text:
return text
ts = str(int(time.time()))
payload = f"{signature}:{ts}:{_checksum4(signature, ts)}"
watermark = _bits_to_zw(_to_bits(payload))
mid = len(text) // 2
return text[:mid] + watermark + text[mid:]
Now, we can use the encode function to create and embed the watermark. Here’s an example:
Hello, how are you?
Here’s the same string with the watermark:
Hello, how are you?
Using a tool such as Invisible Characters, we can easily see that something is “wrong”.
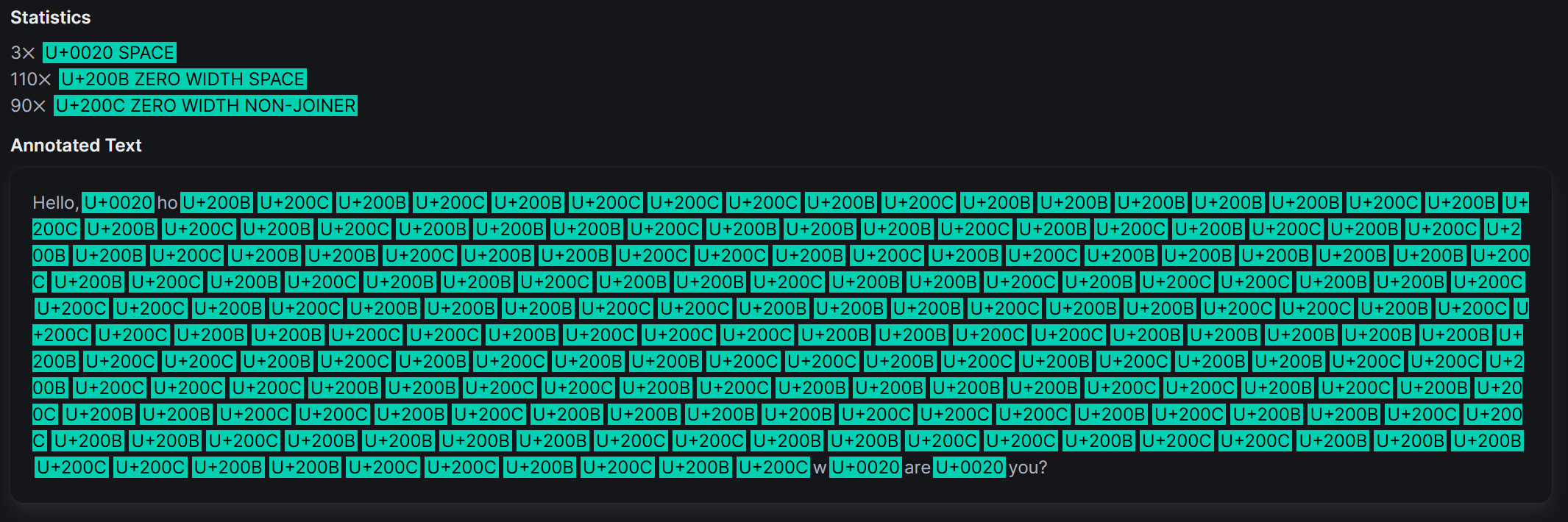
The final piece of the puzzle is a checker that is able to extract the watermark and verify it.
def check(text: str, *, signature: str = SIGNATURE_STR) -> Tuple[bool, Optional[Dict]]:
"""
Detect + validate an invisible watermark in `text`.
"""
if not text:
return False, None
bits = _zw_to_bits(text)
if not bits:
return False, None
raw = _from_bits(bits)
parts = raw.split(":")
info: Dict = {"raw": raw, "valid": False}
if len(parts) >= 3:
sig, ts, chk = parts[0], parts[1], parts[2]
info.update({"signature": sig, "timestamp": int(ts) if ts.isdigit() else None})
if sig == signature and ts.isdigit():
info["valid"] = chk == _checksum4(sig, ts)
info["checksum_match"] = info["valid"]
return True, info
Using the same example string as above, the check function will return:
(
True,
{
'raw': 'WATERMARK:1770555328:0618',
'valid': True,
'signature': 'WATERMARK',
'timestamp': 1770555328,
'checksum_match': True
}
)
Conclusion
While this example demonstrates the most basic approach to text watermarking – model-based ones are significantly more interesting – it highlights the fundamental principle of text watermarking: adding invisible and retrievable markings to texts.
Ignoring the political, societal, and legal questions and implications for a second, text watermarking is also an interesting task to explore both simple concepts such as “ASCII smuggling” as well as highly involved questions related to model training.

Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn