Quick Tip: Beware of Metadata in PDF Exports
PDF files are omnipresent in most of our (professional) lives. They are portable, convenient, compact, and look exactly the way we want them to look on all devices. Also, most software suites, for example Microsoft Office or the Adobe family, allow you to easily export into the PDF format.
This is particularly great for sharing documents. For example, you have written a report in Word and now need to publish (or just send) it to some other people. Sending the file as a PDF will not only make sure that they will definitely be able to open the document, but also that it is (more or less) stable and doesn’t look like a working file. This works great, and I do it all the time! I’ve even written a short article about making your exports look their best!
Metadata in PDF Exports
However, many people seem to not be aware of the fact that most PDF exporters are embedding a lot of metadata into the PDF.
Let’s look at a very common example: Microsoft Word!
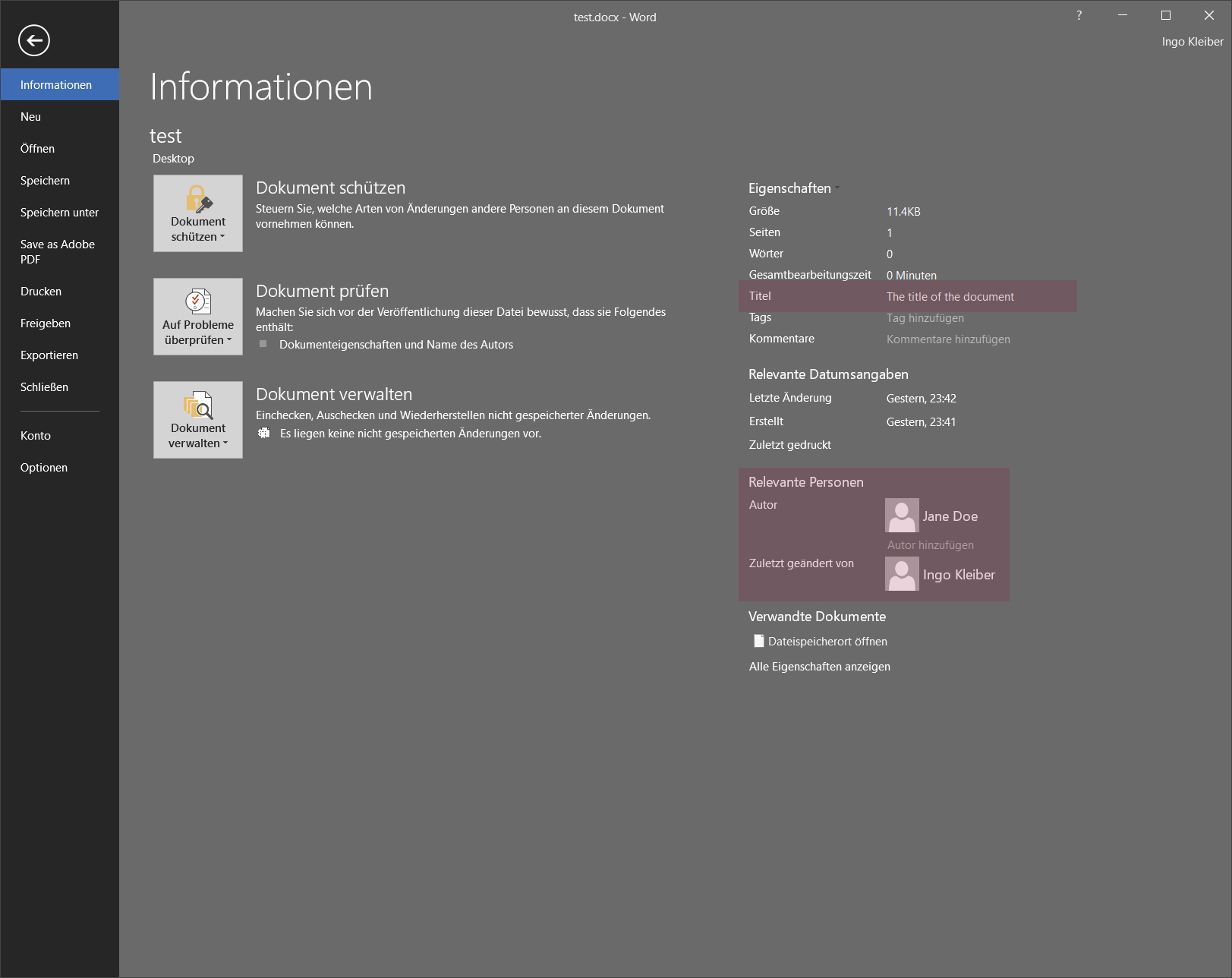
In particular, there are two pieces of metadata which are often overlooked: the title of the document and the list of authors. Essentially, these documents have two titles: the file name (e.g. ‘test.docx’) and the title of the original (source) document. Both, the title and the list of authors, will be baked into the exported file by default. Also, in many cases, the name of the person who created the template (e.g. for a PowerPoint presentation) will also be in that list of authors.
After exporting this file (see above), the following additional information will be in the PDF:
- Author: Jane Doe
- Comments:
- Company:
- CreationDate: D:20190712234237+02’00
- Creator: Acrobat PDFMaker 19 for Word
- Keywords’:
- ModDate’: D:20190712234240+02’00’
- Producer’: Adobe PDF Library 19.10.131
- SourceModified: D:20190712214230
- Subject:
- Title: The title of the document
The ‘Title’ is also what will be shown if the document is opened in a browser (e.g. Chrome or Firefox).

Of course, this is intended behavior and there is nothing particularly wrong with it. However, since this is often overlooked, the metadata of exported documents often contains (semi-)private information which is (most certainly) not intended for the audience of the PDF.
Three Examples and Potential Security Implications
In order to demonstrate this, I’ve randomly downloaded three public PDF documents and checked their metadata. I’ve also attached a simple Python script below that extracts the information.
Example 1: Koalitionsvertrag zwischen CDU, CSU und SPD (19. Legislaturperiode)
This document outlining the coalition between the two ruling coalition parties in Germany was downloaded from Germany’s federal government website.
The document’s title (according to the metadata) is Microsoft Word - Koalitionsvertrag_060318_mit Zeilennummern (002).docx. The document was created by a person named nadine.hunke.
While this is not particularly interesting at first glance, we have (probably) learned how files are internally named (including what looks to be a date that predates the release of the document), which software is used, and how usernames seem to be constructed. We have also identified a person who is not named in the document itself. Also there seems to be a version without Zeilennummern (line numbers) and possibly also a ‘(001)’ version.
Example 2: Digitale Kompetenz Lehrender (EU)
Looking at a fairly recent EU document on the DigCompEdu project, similar information can be extracted.
The document’s title (metadata) is PowerPoint Presentation and the author is Grainne Mulhern. This is, again, not particularly interesting. However, we’ve seen that the EU seems to use PowerPoint to design their leaflets and that Grainne Mulhern, an, according to LinkedIn, ‘Info and Communication Assistant’, was involved in creating this document.
Example 3: Standard Eurobarometer 83, Spring 2015 (EU)
Looking at another EU document, we can learn that even large supranational entities sometimes rely on the dreaded ‘_final’ file names.
This particular document with the title (metadata) Microsoft Word - FirstResultsEB833COMMstandardEN_final.docx was created by someone called BuhlM and exported via Acrobat Distiller 10.1.5 (Windows).
Again, we’ve gained some insight into who creates these documents, which naming schemes are used, and which version of Acrobat is installed.
Security Implications
These types of metadata might seem neglectable, but could potentially be used in a social engineering scenario:
- Information about the way usernames are constructed (e.g. first_name.last_name in a domain) could be revealed.
- Information about how documents are internally named could be revealed. This could be used by attackers to make phishing attempts look more legitimate.
- Information about internal project names (or accounts etc.) could be revealed in the title. These could be used by an attacker to convince employees of their legitimacy.
- Information about employees who are not listed publicly could be revealed. This could also be used to gain credibility.
- Information about the software used could be revealed. This could be particularly interesting if the particular version of the software is outdated or vulnerable.
Even if none of these apply to you, having an important document titled something_final_final.docx just looks unprofessional.
All of that being said, embedding this type of metadata by default makes a lot of sense. We just need to make sure that we’re aware of it and to use it as it is intended.
The data was extracted using a very simple Python script:
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
def mine_pdf(file):
fp = open(file, 'rb')
parser = PDFParser(fp)
doc = PDFDocument(parser)
return doc.info
print(mine_pdf('test.pdf'))
Thank you for visiting!
I hope, you are enjoying the article! I'd love to get in touch! 😀
Follow me on LinkedIn